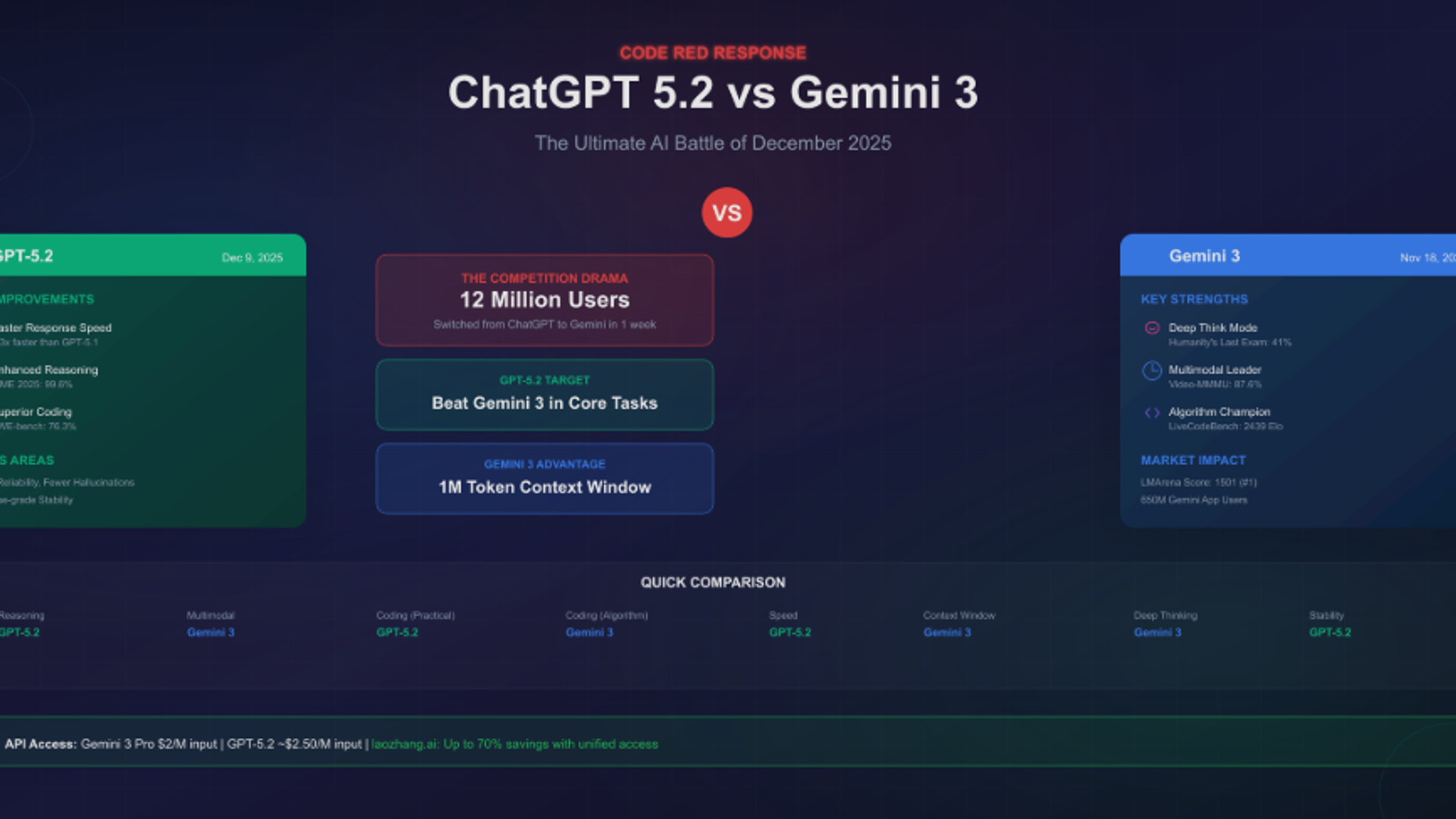
Executive Summary
Key Takeaways
- GPT-5.2 outperforms Gemini 3 Pro in coding, professional knowledge work, and abstract reasoning
- Gemini 3 Pro maintains advantages in multimodal tasks and context length
- GPT-5.2 achieved expert-level performance on 70.9% of professional tasks vs Gemini 3 Pro's 53.3%
- Both models are now considered neck-and-neck in overall capabilities, with specific strengths in different areas
The "Code Red" Context
OpenAI's rapid release came after CEO Sam Altman issued an internal "Code Red" directive following Gemini 3 Pro's strong performance on LMArena leaderboards and other benchmarks. The emergency mobilization accelerated GPT-5.2's development, which arrived less than one month after GPT-5.1 (released November 12, 2025).
Comprehensive Benchmark Comparison Tables
Table 1: Professional Knowledge Work Performance
The GDPval benchmark measures performance on well-specified knowledge work tasks across 44 occupations, including spreadsheet creation, document drafting, and presentation building.
| Model | GDPval Score | Performance vs Experts | Speed Advantage | Cost Advantage |
|---|---|---|---|---|
| GPT-5.2 Thinking | 70.9% | Beats/ties 70.9% of time | 11x faster | <1% of cost |
| Claude Opus 4.5 | 59.6% | Beats/ties 59.6% of time | Not disclosed | Not disclosed |
| Gemini 3 Pro | 53.3% | Beats/ties 53.3% of time | Not disclosed | Not disclosed |
| GPT-5 | 38.8% | Beats/ties 38.8% of time | — | — |
Winner: GPT-5.2 - Achieves first-ever expert-level performance on professional knowledge work tasks with 17.6 percentage point lead over Gemini 3 Pro.
Table 2: Software Engineering & Coding Benchmarks
| Benchmark | GPT-5.2 Thinking | Gemini 3 Pro | Claude Opus 4.5 | GPT-5.1 Thinking |
|---|---|---|---|---|
| SWE-Bench Pro | 55.6% | 43.3% | 52.0% | 50.8% |
| SWE-Bench Verified | 80.0% | Not disclosed | 80.9% | 76.3% |
| Terminal-bench 2.0 | Not disclosed | Not disclosed | 59.3% | Not disclosed |
Analysis
- GPT-5.2 leads Gemini 3 Pro by 12.3 percentage points on SWE-Bench Pro
- Claude Opus 4.5 maintains slight edge on SWE-Bench Verified (80.9% vs 80.0%)
- GPT-5.2 improved 4.8 points over its predecessor on SWE-Bench Pro
- Anthropic leads in command-line coding proficiency (Terminal-bench 2.0)
Winner: GPT-5.2 vs Gemini 3 Pro - Clear advantage in real-world software engineering tasks
Table 3: Abstract Reasoning & Logic
Abstract reasoning measures fluid intelligence and novel problem-solving without relying on memorization.
| Benchmark | GPT-5.2 Thinking | GPT-5.2 Pro | Gemini 3 Pro | Gemini 3 Deep Think | Claude Opus 4.5 | GPT-5.1 |
|---|---|---|---|---|---|---|
| ARC-AGI-2 | 52.9% | 54.2% | 31.1% | 45.1% | 37.6% | 17.6% |
| ARC-AGI-1 | 86.2% | 90.5% | 75.0% | Not disclosed | Not disclosed | Not disclosed |
| Humanity's Last Exam | Not disclosed | Not disclosed | 37.5% | 41.0% | Not disclosed | 26.5% |
Key Insights
- GPT-5.2 Pro achieved 90.5% on ARC-AGI-1, the first model to cross 90% threshold
- GPT-5.2 Thinking improved 200% over GPT-5.1 on ARC-AGI-2 (52.9% vs 17.6%)
- GPT-5.2 surpasses Gemini 3 Pro by 21.8 points on ARC-AGI-2
- Gemini 3 Deep Think leads on Humanity's Last Exam (41.0% without tools)
Winner: GPT-5.2 - Dramatic breakthrough in abstract reasoning, especially on ARC-AGI benchmarks
Table 4: Mathematical Reasoning
| Benchmark | GPT-5.2 Thinking | GPT-5.2 Pro | Gemini 3 Pro (with tools) | GPT-5.1 | Details |
|---|---|---|---|---|---|
| AIME 2025 | 100% | 100% | 100% | 94% | Competition mathematics (30 problems) |
| FrontierMath | 40.3% | Not disclosed | Not disclosed | 31.0% | Research-level mathematics |
| FrontierMath (Tier 1-4) | 14.6% | Not disclosed | 18.8% | Not disclosed | Hardest tier problems |
Analysis
- GPT-5.2 achieved perfect 100% on AIME 2025 without tools, matching Gemini 3 Pro's performance with code execution enabled
- 9.3 percentage point improvement over GPT-5.1 on FrontierMath
- Gemini 3 Pro maintains slight edge on hardest tier problems (18.8% vs 14.6%)
- Both models show exceptional mathematical reasoning capability
Winner: Tie - Both achieve perfect AIME scores, with trade-offs at highest difficulty levels
Table 5: Graduate-Level Scientific Knowledge
GPQA Diamond tests PhD-level scientific understanding across physics, chemistry, and biology.
| Model | GPQA Diamond Score | Improvement vs Previous |
|---|---|---|
| GPT-5.2 Pro | 93.2% | +5.1% vs GPT-5.1 |
| Gemini 3 Deep Think | 93.8% | — |
| GPT-5.2 Thinking | 92.4% | +4.3% vs GPT-5.1 |
| Gemini 3 Pro | 91.9% | — |
| GPT-5.1 Thinking | 88.1% | — |
| Claude Opus 4.5 | 87.0% | — |
Analysis
- Gemini 3 Deep Think holds slight lead (93.8%)
- GPT-5.2 Pro nearly matches at 93.2% (0.6 point difference)
- GPT-5.2 Thinking surpasses Gemini 3 Pro by 0.5 points (92.4% vs 91.9%)
- Essentially tied performance at the highest level of scientific reasoning
Winner: Virtually Tied - Margin of difference negligible at this performance level
Table 6: Visual & Multimodal Understanding
| Benchmark | GPT-5.2 | Gemini 3 Pro | GPT-5.1 | Focus Area |
|---|---|---|---|---|
| CharXiv Reasoning | 88.7% | 81.4% | 80.3% | Scientific diagram interpretation |
| ScreenSpot-Pro | 86.3% | Not disclosed | 64.2% | UI element understanding |
| MMMU-Pro | ~76% | 81.0% | 76% | Multi-modal understanding |
| Video-MMMU | Not disclosed | 87.6% | Not disclosed | Video understanding |
Analysis
- GPT-5.2 leads in scientific figure interpretation (+7.3 points over Gemini)
- GPT-5.2 shows dramatic 22.1 point improvement in UI understanding
- Gemini 3 Pro maintains advantage in comprehensive multimodal benchmarks
- Gemini excels particularly in video understanding with unified architecture
Winner: Split Decision
- GPT-5.2: Static visual reasoning and diagram analysis
- Gemini 3 Pro: Comprehensive multimodal (especially video/audio)
Table 7: Tool Use & Agentic Performance
| Benchmark | GPT-5.2 Thinking | GPT-5.1 Thinking | Gemini 3 Pro | Description |
|---|---|---|---|---|
| Tau2-bench-Telecom | 98.7% | 95.6% | Not disclosed | Multi-tool customer service scenarios |
| 4-Needle MRCR (256K tokens) | ~100% | Not disclosed | Not disclosed | Long-context information retrieval |
| Vending-Bench 2 | Not disclosed | $2,021 net worth | $5,478 (+272%) | Year-long agentic simulation |
Key Insights
- GPT-5.2 achieved near-perfect tool calling accuracy (98.7%)
- First model to reach ~100% on 4-Needle test at 256,000 tokens
- Gemini 3 Pro demonstrated superior long-horizon planning on Vending-Bench 2
- Gemini's 272% higher net worth indicates better sustained decision-making
Winner: Mixed Results
- GPT-5.2: Tool calling precision and long-context retrieval
- Gemini 3 Pro: Long-horizon agentic planning and consistency
Table 8: Error Rates & Reliability
| Metric | GPT-5.2 Thinking | GPT-5.1 Thinking | Improvement |
|---|---|---|---|
| Responses with ≥1 Error | 6.2% | 8.8% | -30% |
| Error Rate Reduction | — | Baseline | 38% fewer errors overall |
| Hallucination Frequency | Lower | Baseline | 30% reduction |
Analysis
- GPT-5.2 produces significantly more reliable outputs
- 30% reduction in error-containing responses
- Particularly important for professional decision-making and research applications
- Makes model "more dependable for everyday knowledge work"
Winner: GPT-5.2 - Substantial reliability improvements over predecessor
Table 9: Context Window & Processing Capacity
| Feature | GPT-5.2 | Gemini 3 Pro | Advantage |
|---|---|---|---|
| Context Window | 400,000 tokens | 1,000,000 tokens | Gemini (+150%) |
| Max Output | 128,000 tokens | Not disclosed | Likely similar |
| Context Quality | Improved coherence | Standard | GPT-5.2 |
| Knowledge Cutoff | August 31, 2025 | Not disclosed | GPT-5.2 (recency) |
Analysis
- Gemini 3 Pro can process 2.5x more content in single request
- Gemini's 1M token window can handle entire books or massive codebases
- GPT-5.2 focuses on better utilization of existing context
- GPT-5.2 less prone to "losing track" in long conversations
Winner: Gemini 3 Pro - Significantly larger context window for document-heavy workflows
Table 10: API Pricing Comparison (Per Million Tokens)
| Model Tier | Input Cost | Output Cost | vs Previous Generation |
|---|---|---|---|
| GPT-5.2 Thinking | $1.75 | $14 | +40% vs GPT-5.1 |
| GPT-5.2 Pro | $21 | $168 | +40% vs GPT-5 Pro |
| Gemini 3 Pro | $2.00 | $12 | — |
| Claude Opus 4.5 | $5.00 | $25 | — |
| GPT-5.1 Thinking | $1.25 | $10 | Reference |
Cost Analysis
- GPT-5.2 Thinking slightly cheaper than Gemini 3 Pro on input (-12.5%)
- GPT-5.2 more expensive on output vs Gemini (+16.7%)
- Both significantly cheaper than Claude Opus 4.5
- 40% price increase justified by 30% error reduction and higher quality
- Cached inputs receive 90% discount for both models
Winner: Gemini 3 Pro - Better pricing, especially for output-heavy applications
Head-to-Head: Strengths & Weaknesses
GPT-5.2 Strengths
- Professional Knowledge Work - Industry-leading 70.9% on GDPval benchmark
- Coding Excellence - 55.6% on SWE-Bench Pro vs Gemini's 43.3%
- Abstract Reasoning - Breakthrough 52.9% on ARC-AGI-2, 21.8 points ahead
- Reliability - 30% fewer errors than predecessor, 38% overall error reduction
- Tool Calling - Near-perfect 98.7% accuracy on complex multi-tool scenarios
- Long Context Retrieval - First to achieve ~100% on 4-Needle MRCR at 256K tokens
- Scientific Diagrams - 88.7% on CharXiv vs Gemini's 81.4%
- Speed - Delivers results 11x faster than human experts on knowledge work
GPT-5.2 Weaknesses
- Multimodal Breadth - Weaker on comprehensive multimodal benchmarks (76% vs 81%)
- Context Window - 400K tokens vs Gemini's 1M tokens (60% smaller)
- Video Understanding - No unified video architecture like Gemini
- Long-Horizon Planning - Lower performance on Vending-Bench 2 agentic simulation
- API Pricing - 40% more expensive than GPT-5.1, slightly higher output costs vs Gemini
- Image Generation - No improvements announced; still uses DALL-E 3
- Hardest Math - Trails Gemini on FrontierMath Tier 1-4 (14.6% vs 18.8%)
Gemini 3 Pro Strengths
- Multimodal Architecture - Unified handling of text, images, audio, video
- Context Window - 1 million tokens can process entire books/repositories
- MMMU-Pro - 81.0% vs GPT's ~76% in comprehensive multimodal understanding
- Video Analysis - 87.6% on Video-MMMU with temporal reasoning
- Long-Horizon Agents - 272% higher net worth on Vending-Bench 2
- Pricing - Competitive $2/$12 per million tokens
- Google Integration - Seamless across Google Cloud, Maps, BigQuery via MCP
- Scientific Knowledge - 93.8% with Deep Think mode (highest available)
- Humanity's Last Exam - 41.0% without tools, leading on hardest reasoning test
Gemini 3 Pro Weaknesses
- Professional Tasks - 53.3% vs GPT-5.2's 70.9% on GDPval (17.6 point gap)
- Coding - 43.3% on SWE-Bench Pro vs GPT-5.2's 55.6% (12.3 point deficit)
- Abstract Reasoning - 31.1% on ARC-AGI-2 vs GPT-5.2's 52.9% (21.8 point gap)
- Market Perception - Lost top LMArena position to GPT-5.2 release
- Tool Calling Precision - No comparable public benchmarks to GPT's 98.7%
- UI Understanding - Weaker on ScreenSpot-Pro tasks
Use Case Recommendations
Choose GPT-5.2 Thinking When:
✅ Coding & Software Development - Superior performance on real-world engineering tasks
✅ Professional Knowledge Work - Spreadsheets, presentations, complex document creation
✅ Abstract Problem-Solving - Novel challenges requiring fluid intelligence
✅ Tool-Heavy Workflows - Applications requiring precise multi-tool orchestration
✅ Error-Sensitive Applications - Research, analysis, decision support where reliability critical
✅ Long-Context Information Retrieval - Finding specific information in 200K+ token documents
✅ Scientific Figure Analysis - Interpreting complex diagrams, charts, technical illustrations
Choose Gemini 3 Pro When:
✅ Multimodal Projects - Heavy use of images, audio, video alongside text
✅ Massive Documents - Processing entire books, large codebases, extensive research papers
✅ Video Analysis - Understanding temporal sequences, visual narratives
✅ Long-Horizon Agents - Tasks requiring sustained decision-making over extended periods
✅ Google Ecosystem - Deep integration with Google Cloud services needed
✅ Cost-Sensitive Deployments - Lower pricing for high-volume output generation
✅ Graduate-Level Science - Maximum scientific knowledge (93.8% with Deep Think)
✅ Extreme Reasoning - Humanity's Last Exam-type challenges (41% without tools)
Model Variants Explained
GPT-5.2 Variants
GPT-5.2 Instant
- Optimized for: Speed, information retrieval, how-tos, study guides
- Use cases: Quick questions, translations, skill-building
- Latency: ~40% faster than Thinking mode
- Best for: Everyday work and learning
GPT-5.2 Thinking
- Optimized for: Complex reasoning, professional tasks
- Use cases: Coding, document analysis, multi-step projects
- Performance: Featured in most benchmarks
- Best for: Professional knowledge work
GPT-5.2 Pro
- Optimized for: Maximum accuracy and reliability
- Use cases: Mission-critical programming, research
- Performance: Highest scores on most benchmarks
- Best for: Domains requiring utmost precision
Gemini 3 Modes
Gemini 3 Pro (Standard)
- Standard reasoning and processing
- Featured in most benchmark comparisons
- Balanced speed and capability
Gemini 3 Deep Think
- Extended reasoning time for complex problems
- Achieves highest scores on science and reasoning
- Trades speed for maximum accuracy
Real-World Performance Insights
Enterprise Feedback: GPT-5.2
Data Science Platforms
- Databricks, Hex, Triple Whale: "Exceptional at agentic data science"
- 40% faster document information extraction (Box)
- 40% boost in reasoning accuracy for Life Sciences (Box)
Coding Tools
- Cognition, Warp, Charlie Labs, JetBrains: "State-of-the-art agentic coding"
- Measurable improvements in interactive coding and bug finding
- Better at multi-step code refactoring
Knowledge Management
- Notion, Shopify, Harvey, Zoom: "State-of-the-art long-horizon reasoning"
- Improved tool-calling performance across platforms
Enterprise Feedback: Gemini 3 Pro
Google Ecosystem Integration
- Seamless MCP servers for Maps, BigQuery
- Better than GPT for automated presentation generation (Google Labs Mixboard)
- Native integration across Google Workspace
Multimodal Workflows
- Superior for video analysis and visual interpretation
- Better text rendering in generated images
- Stronger performance on image-heavy documents
Independent Verification Status
Important Context: Most benchmarks in this comparison are vendor-reported. Independent verification is ongoing as of December 2025. Key considerations:
- OpenAI Benchmarks - GDPval is OpenAI's proprietary benchmark
- Google Benchmarks - Some Gemini scores use Deep Think mode vs standard comparisons
- Contamination Risk - Both models may have been optimized for public benchmarks
- Real-World Performance - May differ from controlled benchmark conditions
Third-party evaluations from LMArena, Humanity's Last Exam, and other independent sources show both models performing at similar levels, with specific advantages in different domains.
Technical Specifications Comparison
| Specification | GPT-5.2 | Gemini 3 Pro |
|---|---|---|
| Architecture | Transformer-based with reasoning tokens | Unified multimodal transformer |
| Context Window | 400,000 tokens | 1,000,000 tokens |
| Max Output | 128,000 tokens | Not disclosed |
| Modalities | Text, images | Text, images, audio, video |
| Knowledge Cutoff | August 31, 2025 | Not publicly disclosed |
| Reasoning Mode | Yes (Thinking mode) | Yes (Deep Think mode) |
| Release Date | December 11, 2025 | Mid-November 2025 |
| Pretraining Improvements | Confirmed | Confirmed |
| Post-training Improvements | Confirmed | Confirmed |
Competitive Landscape Analysis
Market Position December 2025
Before GPT-5.2 Release
- Gemini 3 Pro - Leading on LMArena leaderboard
- Claude Opus 4.5 - Strong on coding (SWE-Bench Verified)
- GPT-5.1 - Sixth place on LMArena
- Grok 3 (xAI) - Competitive in select benchmarks
After GPT-5.2 Release
- GPT-5.2 reclaimed performance leadership in most categories
- Three-way competition between OpenAI, Google, Anthropic
- Each company leapfrogging others every few months
- No single clear winner across all domains
Development Velocity
Release Timeline
- GPT-5: August 7, 2025
- GPT-5.1: November 12, 2025 (3 months later)
- Gemini 3 Pro: Mid-November 2025
- Claude Opus 4.5: November 24, 2025
- GPT-5.2: December 11, 2025 (less than 1 month after 5.1)
This unprecedented pace suggests:
- Intense competitive pressure driving rapid iteration
- Significant remaining room for AI capability improvements
- High compute and development costs
- Market leaders pushing boundaries simultaneously
Future Outlook
OpenAI Roadmap
- Project Garlic: More fundamental architectural shift targeting early 2026
- Image Generation: Improvements promised but not in GPT-5.2
- Consumer Features: Better personality, speed improvements expected January 2026
- Safety: Enhanced mental health response and teen age verification
Google Gemini Development
- Nano Banana Pro: Enhanced image generation already released
- Google Integration: Continued deepening across product ecosystem
- MCP Servers: Expanding agent connectivity to Google services
- Multimodal Leadership: Likely to maintain video/audio advantage
Competitive Dynamics
- Models now updated every 3-6 weeks at frontier
- $1.4+ trillion infrastructure investments from OpenAI
- Google leveraging existing cloud infrastructure
- Anthropic focusing on safety and coding excellence
- Winner depends on specific deployment needs, not universal superiority
Conclusion: Which Model Wins?
The Verdict: Context-Dependent Tie
Neither GPT-5.2 nor Gemini 3 Pro can claim universal superiority. The choice depends entirely on your specific use case:
GPT-5.2 Wins For:
- Professional knowledge workers needing maximum reliability
- Software engineers requiring best-in-class coding assistance
- Applications demanding abstract reasoning and novel problem-solving
- Users prioritizing error reduction and factual accuracy
- Tool-heavy workflows requiring precise orchestration
Gemini 3 Pro Wins For:
- Multimodal applications involving video, audio, images
- Processing massive documents (entire books, large codebases)
- Long-horizon agentic tasks requiring sustained planning
- Google Cloud ecosystem integration
- Cost-conscious deployments with high output volume
Both Excel At:
- Graduate-level scientific reasoning (93%+ performance)
- Competition mathematics (100% AIME 2025)
- Complex professional tasks
- Multi-step logical reasoning
For most enterprise applications, evaluate both models against your specific workload before committing. The 12-point coding advantage, 17-point professional work lead, and 30% error reduction make GPT-5.2 the current front-runner for text-based knowledge work, while Gemini 3 Pro remains superior for multimedia and massive-document applications.
Frequently Asked Questions
Q: Is GPT-5.2 always better than Gemini 3 Pro?
A: No. GPT-5.2 leads in coding, professional work, and abstract reasoning. Gemini 3 Pro excels at multimodal tasks, video understanding, and processing very large documents.
Q: How much does each model cost?
A: GPT-5.2 Thinking costs $1.75/$14 per million input/output tokens. Gemini 3 Pro costs $2.00/$12 per million tokens. For most use cases, pricing is comparable.
Q: Which model is faster?
A: Both offer fast response times. GPT-5.2 claims 11x faster than human experts on knowledge work. Gemini 3 also emphasizes low latency. Real-world speed depends on task complexity.
Q: Can I use both models?
A: Yes. Many organizations use GPT-5.2 for coding/analysis and Gemini 3 for multimodal workflows, selecting the best tool for each task.
Q: What about Claude Opus 4.5?
A: Claude Opus 4.5 leads on SWE-Bench Verified (80.9%), Terminal-bench 2.0 (59.3%), and prompt injection resistance. It's the most expensive option but excels at specific coding tasks.
Q: Will these models improve further?
A: Yes. OpenAI plans Project Garlic for early 2026. Google continues enhancing Gemini. Expect major updates every 1-2 months given current competitive intensity.
Q: Which model is more reliable?
A: GPT-5.2 shows 30% fewer error-containing responses vs GPT-5.1. Specific reliability comparisons with Gemini 3 Pro await independent verification.
Q: Does model choice affect business outcomes?
A: Yes, significantly. Box reported 40% faster document processing and 40% higher reasoning accuracy in healthcare applications using GPT-5.2. Choose based on your specific metrics.
Last Updated: December 12, 2025 | All benchmark data from vendor announcements and third-party evaluations | Independent verification ongoing



