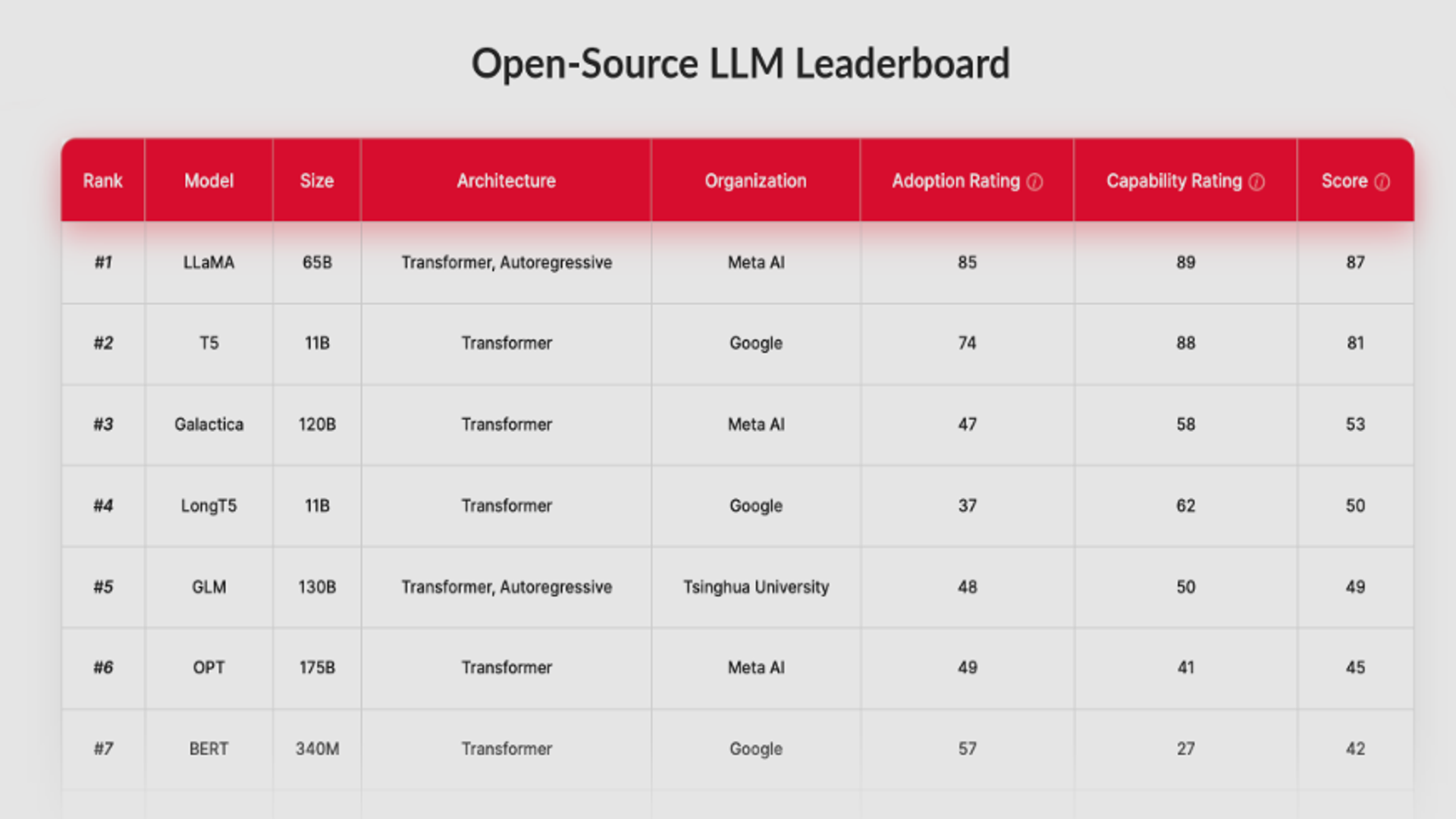
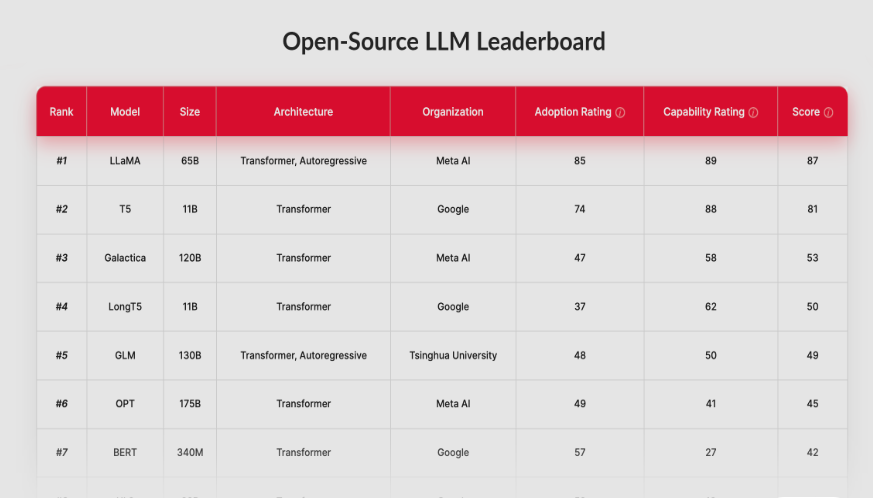
| Model | Params | MMLU | MMLU-Pro | HumanEval | SWE-bench | LiveCodeBench | AIME 2025 | GPQA ◇ | Arena |
|---|---|---|---|---|---|---|---|---|---|
| GLM-4.7 | 355B | 90.1 | 84.3 | 94.2 | 73.8 | 84.9 | 95.7 | 85.7 | 1445 |
| GLM-5 | 744B | 85.0 | 70.4 | 90.0 | 77.8 | 52.0 | 84.0 | 86.0 | 1451 |
| Kimi K2.5 | 1T | 92.0 | 87.1 | 99.0 | 76.8 | 85.0 | 96.1 | 87.6 | 1447 |
| MiniMax M2.5 | 230B | 85.0 | 76.5 | 89.6 | 80.2 | 65.0 | 86.3 | 85.2 | — |
| DeepSeek V3.2 | 685B | 88.5 | 85.0 | — | 67.8 | 74.1 | 89.3 | 79.9 | 1421 |
| Step-3.5-Flash | 196B | — | — | — | 74.4 | 86.4 | 97.3 | — | — |
| Qwen 3.5 | 397B | 88.5 | 87.8 | — | 76.4 | 83.6 | — | 88.4 | — |
| MiMo-V2-Flash | 309B | 86.7 | 84.9 | 84.8 | 73.4 | 80.6 | 94.1 | 83.7 | 1401 |
| DeepSeek R1 | 671B | 90.8 | 84.0 | 90.2 | — | 65.9 | 87.5 | 71.5 | 1398 |
| Qwen 3 235B | 235B | — | 84.4 | — | — | 74.1 | 92.3 | 81.1 | 1422 |
| GPT-oss 120B | 117B | 90.0 | 90.0 | — | 62.4 | 60.0 | — | 80.9 | 1354 |
| Mistral Large | 675B | 85.5 | — | 92.0 | — | 82.8 | 88.0 | 43.9 | 1416 |
| Llama 4 Maverick | 400B | 85.5 | 80.5 | 62.0 | — | 43.4 | — | 69.8 | 1328 |
| Gemma 3 27B | 27B | — | 67.5 | — | — | 29.7 | — | 42.4 | 1365 |
Choosing the right open-source large language model in 2026 has never been harder — or more exciting. With over a dozen frontier-class models now publicly available, the gap between open-source and proprietary AI has narrowed to near parity in many domains. But not all open-source LLMs are created equal. Performance varies dramatically depending on the task: a model that tops the coding charts may underperform in mathematical reasoning, and vice versa.
This article breaks down the definitive open-source LLM leaderboard for 2026 — pulling from benchmark scores across MMLU, MMLU-Pro, HumanEval, SWE-bench Verified, LiveCodeBench, AIME 2025, GPQA Diamond, MATH-500, Chatbot Arena, and IFEval — so you can make an informed decision for your specific use case.
The Tier System: How Models Are Ranked
The leaderboard organizes open-source models into four tiers — S, A, B, and C/D — based on aggregate performance across reasoning, coding, math, chat, and instruction following benchmarks. Here's what each tier means in practice:
- S Tier: Frontier-class performance across multiple domains. These models compete directly with leading proprietary systems.
- A Tier: Excellent overall capability with notable strengths in specific areas.
- B Tier: Solid, production-ready models that offer strong value relative to their size.
- C/D Tier: Capable but generally outclassed by higher-tier alternatives in most benchmark categories.
S-Tier Models: The Best Open-Source LLMs in 2026
GLM-4.7 (355B) — Zhipu AI
Standout scores: HumanEval 94.2 | SWE-bench Verified 73.8 | LiveCodeBench 84.9 | AIME 2025 95.7 | GPQA Diamond 85.7 | Chatbot Arena 1445 | IFEval 88.0
GLM-4.7 is the highest-ranked model on the leaderboard for most people's practical needs. Its HumanEval score of 94.2 — the best of any model listed — signals exceptional code generation ability. More impressively, it scores 95.7 on AIME 2025 (the hardest math benchmark tracked), 85.7 on GPQA Diamond (a doctoral-level science reasoning test), and 84.9 on LiveCodeBench (real-world competitive coding). With a 200K context window and strong instruction-following (IFEval: 88.0), GLM-4.7 is arguably the most well-rounded open-source model available as of early 2026.
Best for: Coding agents, complex reasoning, scientific Q&A, multi-turn instruction-following.
GLM-5 (744B) — Zhipu AI
Standout scores: SWE-bench Verified 77.8 | GPQA Diamond 86.0 | Chatbot Arena 1451 | IFEval 88.0
GLM-5 is Zhipu AI's larger successor to GLM-4.7, and it currently holds the highest Chatbot Arena rating on the leaderboard at 1451 — making it the top-ranked model by human preference. It also achieves the best SWE-bench Verified score among Zhipu models (77.8) and edges out GLM-4.7 on GPQA Diamond (86.0 vs. 85.7). However, GLM-5 trades off in LiveCodeBench (52.0 vs. 84.9 for GLM-4.7) and AIME 2025 (84.0 vs. 95.7), suggesting it favors depth and conversation quality over raw coding throughput.
Best for: Conversational AI, software engineering tasks, scientific reasoning at scale.
Kimi K2.5 (1T) — Moonshot
Standout scores: MMLU 92.0 | MMLU-Pro 87.1 | HumanEval 99.0 | LiveCodeBench 85.0 | AIME 2025 96.1 | GPQA Diamond 87.6 | MATH-500 98.0 | Chatbot Arena 1447 | IFEval 94.0
Kimi K2.5 posts some of the most remarkable benchmark numbers on the entire leaderboard. Its HumanEval score of 99.0 is the highest of any model tracked — essentially near-perfect on standard coding evaluation. It also leads in MMLU (92.0), IFEval (94.0), MATH-500 (98.0), and GPQA Diamond (87.6), while maintaining a Chatbot Arena rating of 1447. With a 262K context window and 1 trillion total parameters (32B active per token), it delivers frontier-level capability at a MoE efficiency profile.
Best for: Any task requiring top-tier coding, math, reasoning, or instruction adherence; multi-domain AI applications.
MiniMax M2.5 (230B) — MiniMax
Standout scores: HumanEval 89.6 | SWE-bench Verified 80.2 | AIME 2025 86.3 | GPQA Diamond 85.2 | IFEval 87.5
MiniMax M2.5 earns its S-tier placement primarily on the strength of its SWE-bench Verified score of 80.2 — the highest of any model on the leaderboard for real-world software engineering tasks. This metric evaluates whether a model can resolve actual GitHub issues, making it one of the most practically relevant benchmarks for development teams. With 230B parameters and a 205K context window, M2.5 is also one of the more efficient S-tier models to deploy.
Best for: Software engineering, code review, bug fixing in real-world codebases.
DeepSeek V3.2 (685B) — DeepSeek
Standout scores: MMLU-Pro 85.0 | SWE-bench Verified 67.8 | LiveCodeBench 74.1 | AIME 2025 89.3 | GPQA Diamond 79.9 | Chatbot Arena 1421
DeepSeek V3.2 rounds out the S tier with consistently strong scores across nearly every benchmark category. Its AIME 2025 score of 89.3 and GPQA Diamond of 79.9 show frontier reasoning capability. The model's 1421 Chatbot Arena rating — the third-highest on the board after GLM-5 and Kimi K2.5 — reflects strong human preference for its conversational quality. DeepSeek V3.2 is released under the MIT License, making it one of the most commercially permissive S-tier options available.
Best for: General reasoning, agentic workflows, teams prioritizing open licensing.
Step-3.5-Flash (196B) — Stepfun
Standout scores: SWE-bench Verified 74.4 | LiveCodeBench 86.4 | AIME 2025 97.3
Step-3.5-Flash is a sleeper hit on the leaderboard. At only 196B parameters — smaller than most of its S-tier peers — it posts an AIME 2025 score of 97.3, the highest on the entire board alongside GLM-4.7, and a LiveCodeBench of 86.4, which also ranks near the top. Its SWE-bench score of 74.4 confirms strong real-world coding ability. For teams running compute-constrained deployments, Step-3.5-Flash offers exceptional reasoning per parameter.
Best for: Math-heavy applications, competitive coding, efficient deployment at scale.
A-Tier Models: Excellent All-Arounders
Qwen 3.5 (397B) — Qwen (Alibaba)
Standout scores: MMLU 88.5 | MMLU-Pro 87.8 | SWE-bench Verified 76.4 | LiveCodeBench 83.6 | GPQA Diamond 88.4 | IFEval 92.6
Qwen 3.5 earns the best GPQA Diamond score of any model on the leaderboard at 88.4 — surpassing even Kimi K2.5 — and posts exceptional IFEval scores (92.6), meaning it follows complex instructions with high fidelity. Its LiveCodeBench score (83.6) and SWE-bench Verified result (76.4) further demonstrate strong coding capability. If your application demands accurate instruction following paired with doctoral-level scientific reasoning, Qwen 3.5 deserves serious evaluation.
Best for: Scientific reasoning, complex instruction-following, multilingual workloads.
MiMo-V2-Flash (309B) — Xiaomi
Standout scores: MMLU 86.7 | MMLU-Pro 84.9 | HumanEval 84.8 | SWE-bench Verified 73.4 | LiveCodeBench 80.6 | AIME 2025 94.1 | GPQA Diamond 83.7 | Chatbot Arena 1401
MiMo-V2-Flash punches above its weight class for an A-tier model. Its AIME 2025 score of 94.1 and GPQA Diamond of 83.7 place it ahead of several B- and C-tier models twice its size. With a 262K context window and strong HumanEval performance (84.8), it's a balanced choice for teams that want quality across all task types without committing to the resource overhead of a 600B+ model.
Best for: Balanced coding and reasoning workloads, high-throughput production serving.
DeepSeek R1 (671B) — DeepSeek
Standout scores: MMLU 90.8 | MMLU-Pro 84.0 | HumanEval 90.2 | LiveCodeBench 65.9 | AIME 2025 87.5 | GPQA Diamond 71.5 | MATH-500 97.3 | Chatbot Arena 1398
The model that sparked the 2025 "DeepSeek moment," R1 remains a powerful choice — especially for math-heavy applications (MATH-500: 97.3) and general knowledge tasks (MMLU: 90.8). It has since been surpassed by DeepSeek V3.2 on several benchmarks, but its combination of strong HumanEval (90.2) and top-tier MATH-500 scores makes it still relevant for workflows where mathematical reasoning is primary.
Best for: Mathematics, general reasoning, workflows already integrated with the DeepSeek ecosystem.
Qwen 3 235B — Qwen (Alibaba)
Standout scores: MMLU-Pro 84.4 | LiveCodeBench 74.1 | AIME 2025 92.3 | GPQA Diamond 81.1 | Chatbot Arena 1422 | IFEval 87.8
Qwen 3 235B is a strong all-around performer with a Chatbot Arena rating of 1422 and an AIME 2025 score of 92.3. It's the more accessible sibling of Qwen 3.5, offering similar reasoning depth at roughly 40% fewer parameters — a meaningful advantage for teams managing GPU costs.
Best for: Cost-efficient reasoning and chat applications at large scale.
B-Tier Models: Solid Production Options
GPT-oss 120B — OpenAI
Standout scores: MMLU 90.0 | MMLU-Pro 90.0 | SWE-bench Verified 62.4 | LiveCodeBench 60.0 | GPQA Diamond 80.9 | Chatbot Arena 1354
OpenAI's first fully open-weight release since GPT-2 stands out for its MMLU-Pro score of 90.0 — the highest on the entire leaderboard in that benchmark — and GPQA Diamond of 80.9. It trails in coding-specific benchmarks like LiveCodeBench (60.0) and SWE-bench (62.4), which pulls it into B tier. However, for general knowledge tasks and scientific understanding, it's among the strongest options available. Its Apache 2.0 license makes it one of the most commercially permissive models on the board.
Best for: General knowledge applications, scientific QA, teams that prefer OpenAI-origin models with open licensing.
Mistral Large (675B) — Mistral
Standout scores: HumanEval 92.0 | LiveCodeBench 82.8 | AIME 2025 88.0 | MATH-500 93.6 | Chatbot Arena 1416
Mistral Large posts impressive coding numbers — HumanEval 92.0 and LiveCodeBench 82.8 — but its GPQA Diamond score of 43.9 is notably weaker than its peers, limiting its overall tier placement. For teams focused primarily on code generation and math rather than scientific reasoning, Mistral Large is a capable and battle-tested choice with a 256K context window.
Best for: Code generation, math tasks, teams already in the Mistral ecosystem.
Nvidia Nemotron Ultra 253B and Super 49B
The Nvidia Nemotron series offers something unique: strong benchmark performance at much smaller parameter counts. Nemotron Super 49B achieves a MATH-500 of 97.4 (matching DeepSeek R1), Nemotron Ultra 253B posts solid GPQA Diamond (76.0) and IFEval (89.5) results, and Nemotron Nano 30B packs an MMLU-Pro of 78.1 into just 30B parameters. Nemotron Nano also supports a 1M token context window — the joint-longest on the board alongside Llama 4 Maverick. For deployment on constrained hardware, the Nemotron line deserves serious consideration.
Best for: Edge deployment, resource-constrained environments, math-heavy smaller model workloads.
Complete Benchmark Score Reference
Scores sourced from official model technical reports. — indicates benchmark not reported by the model's authors.
Choosing the Right Open-Source LLM for Your Use Case
Best for Coding
Kimi K2.5 (HumanEval: 99.0) and GLM-4.7 (HumanEval: 94.2, LiveCodeBench: 84.9) are the strongest performers for code generation and software engineering tasks. For real-world bug fixing and PR resolution, MiniMax M2.5 leads on SWE-bench Verified (80.2).
Best for Math
Step-3.5-Flash and GLM-4.7 share the top AIME 2025 score (97.3 and 95.7 respectively). Kimi K2.5 leads MATH-500 at 98.0. Nemotron Super 49B achieves a MATH-500 of 97.4 at just 49B parameters — the best efficiency ratio on the board.
Best for Reasoning and Science
Qwen 3.5 tops GPQA Diamond at 88.4, followed by Kimi K2.5 (87.6) and GLM-5 (86.0). These models are best suited for doctoral-level scientific QA, medical applications, and complex multi-step reasoning tasks.
Best for Conversational AI
By Chatbot Arena ELO — the gold standard for human preference — GLM-5 (1451), Kimi K2.5 (1447), and GLM-4.7 (1445) are the top three. All three are strong choices for chat interfaces, customer-facing assistants, and dialogue-heavy applications.
Best for Instruction Following
Kimi K2.5 leads IFEval at 94.0, followed by Qwen 3.5 (92.6) and Nemotron Ultra (89.5). For applications where precise, reliable adherence to complex system prompts is critical — such as RAG pipelines, structured output generation, or multi-agent orchestration — these models are the strongest options.
Best for Resource-Constrained Deployments
Gemma 3 27B (Google), Nemotron Nano 30B , and Nemotron Super 49B are the smallest models on the leaderboard that still achieve meaningful benchmark scores. For teams operating without access to multi-GPU infrastructure, these offer the best capability within practical compute limits.
Key Trends in the 2026 Open-Source LLM Landscape
MoE architecture dominance. Nearly every S-tier and A-tier model uses Mixture-of-Experts, activating only a fraction of total parameters per token. This allows models to achieve massive total parameter counts — 400B, 685B, even 1T — while keeping inference costs closer to much smaller dense models.
Long context as table stakes. Most frontier open-source models now offer at least 128K context windows. Several — including Kimi K2.5 (262K), GLM-4.7 and GLM-5 (200K), Mistral Large (256K), and Llama 4 Maverick (1M) — push well beyond this. Long context has moved from a differentiating feature to a baseline expectation.
Coding benchmarks as the new frontier. SWE-bench Verified has emerged as the most practically meaningful coding benchmark, measuring real GitHub issue resolution rather than synthetic problems. The spread between top (MiniMax M2.5: 80.2) and bottom (Llama 4 Maverick: N/A) performers is wide, making it a critical evaluation criterion for engineering-focused teams.
Chatbot Arena as the human preference signal. ELO ratings from Chatbot Arena remain the most reliable proxy for real-world conversational quality, since they capture preference from diverse human evaluators rather than automated metrics. The current top three — GLM-5, Kimi K2.5, and GLM-4.7 — all cluster within a tight 6-point range (1445–1451), suggesting human preference has converged among the best frontier open-source models.
Final Takeaways
The 2026 open-source LLM leaderboard reflects a field that has matured dramatically. S-tier models like GLM-4.7 , Kimi K2.5 , and MiniMax M2.5 are matching or exceeding proprietary model performance on specific benchmarks. Smaller models like Step-3.5-Flash (196B) and Nemotron Super 49B are achieving results that would have required 600B+ parameter models just 12 months ago.
For teams building production AI systems, the practical guidance is straightforward: identify your primary task (coding, reasoning, chat, instruction-following), shortlist the top performers in that benchmark category, and run head-to-head evaluations on your own data before committing. The leaderboard gives you the starting point — your real-world evaluation gives you the answer.