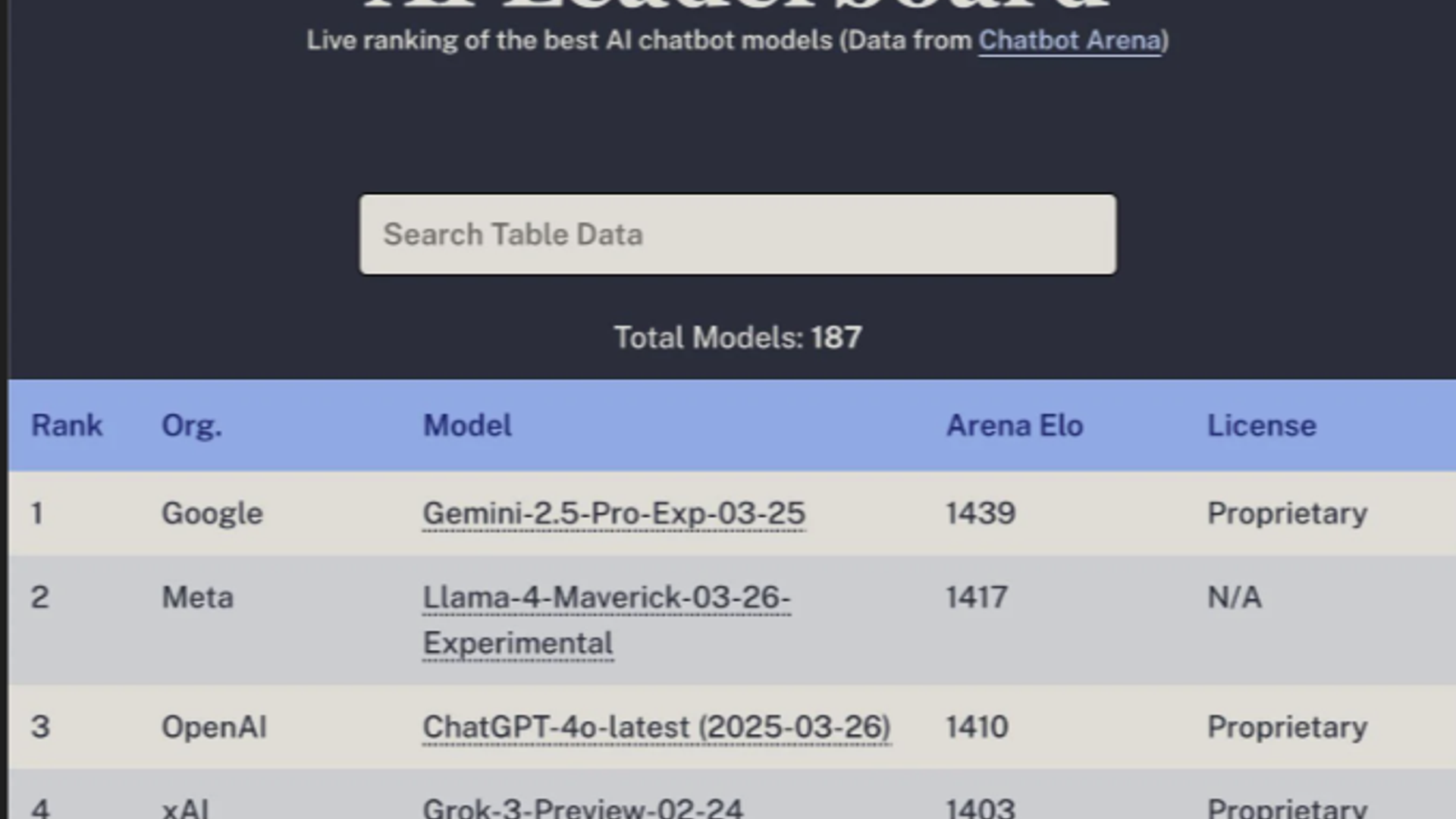
| Model | Intelligence Index | Approx. Price Tier |
|---|---|---|
| Gemini 3.1 Pro Preview | 57 (top) | Premium ($12/M output) |
| Claude Opus 4.6 (max) | 53 | Premium |
| Claude Sonnet 4.6 (max) | 51 | Upper mid |
| GPT-5.2 (xhigh) | High tier | Premium |
| Gemini 3 Flash (Reasoning) | 46 | Mid-tier |
| Gemini 3 Flash | Mid-tier | Low-mid |
| Gemma 3n E4B | Compact | $0.03/M (budget) |
| Nova Micro | Compact | $0.06/M (budget) |
With over 100 large language models now publicly accessible via API, choosing the right AI model has become one of the most consequential decisions an engineering team can make. Pick the wrong model and you pay too much, wait too long, or get outputs that fall short of what your application demands.
Artificial Analysis operates one of the most rigorous and comprehensive AI model leaderboards available — independently measuring every model on the same hardware, under the same conditions, across five critical dimensions: intelligence, output speed, latency, price, and context window . Unlike benchmarks that rely solely on numbers self-reported by AI labs, Artificial Analysis runs all evaluations independently. This article unpacks what their leaderboard reveals about the current state of AI models in 2026.
How Artificial Analysis Measures AI Models
Before diving into rankings, it's worth understanding what separates this leaderboard from others. Every metric on the Artificial Analysis leaderboard is either independently measured or — where self-reported by labs — clearly labelled as such. The platform takes 8 measurements per day for individual requests and 2 per day for parallel requests, with all performance metrics calculated from the past 72 hours of live data. This means rankings reflect real-world API performance today, not theoretical specs from a product launch.
The five dimensions tracked are:
1. Intelligence (Artificial Analysis Intelligence Index v4.0) A composite score built from 10 independently run evaluations spanning agents, coding, scientific reasoning, and general knowledge. This is not a simple average of existing benchmarks — it's a custom-built index designed to capture the full breadth of capabilities that matter in production applications.
2. Output Speed Measured as tokens per second generated after the first token is received. This reflects sustained throughput during generation — the metric that determines how fast your users receive responses.
3. Latency (Time to First Token — TTFT) The time in seconds between when an API request is sent and when the first token arrives. For interactive applications, this is often more important than raw speed — a model that starts responding in 0.2 seconds feels dramatically faster than one that takes 5 seconds to begin, even if both finish at similar times.
4. Price Expressed as USD per million tokens using a blended 3:1 ratio of input to output token prices. This ratio reflects typical usage patterns better than input or output prices alone.
5. Context Window The maximum number of combined input and output tokens a model can process in a single request. Longer context windows enable processing of large documents, entire codebases, or extended conversation histories without truncation.
Intelligence: Who Leads the 2026 AI Rankings?
The Intelligence Index v4.0: A New Standard
The Artificial Analysis Intelligence Index v4.0 is built from 10 evaluations run independently on dedicated hardware:
- GDPval-AA — Real-world agentic work tasks across 44 occupations and 9 industries, measuring whether AI can produce actual professional deliverables: documents, slides, spreadsheets, code, and more
- τ²-Bench Telecom — Agentic tool use in a realistic customer service setting
- Terminal-Bench Hard — Agentic coding and terminal command execution
- SciCode — Scientific coding challenges requiring domain knowledge
- AA-LCR — Long context reasoning across extended documents
- AA-Omniscience — Factual knowledge and hallucination measurement across 6,000 questions in 42 topics spanning business, law, health, software engineering, humanities, and science
- IFBench — Instruction following accuracy
- Humanity's Last Exam (HLE) — Expert-level reasoning and knowledge questions
- GPQA Diamond — Scientific reasoning across biology, physics, and chemistry
- CritPt — Frontier physics reasoning
This architecture is deliberately designed to resist narrow optimization. A model cannot score highly by excelling at just one task type — it must demonstrate broad, reliable capability across agents, coding, knowledge, and reasoning simultaneously.
Top Intelligence Rankings
Gemini 3.1 Pro Preview from Google scores the highest on the Artificial Analysis Intelligence Index with a score of 57, followed by Claude Opus 4.6 (Adaptive Reasoning, Max Effort) with a score of 53, and Claude Sonnet 4.6 (Adaptive Reasoning, Max Effort) with a score of 51.
Gemini 3.1 Pro Preview was released on February 19, 2026. It generates output at 109.5 tokens per second via Google's API, placing it above average among reasoning models in its price tier (median: 71.3 t/s). Its pricing sits at $2.00 per million input tokens and $12.00 per million output tokens via Google's API.
Rounding out the top intelligence tier are GPT-5.2 (xhigh) and Claude Sonnet 4.6 (max) , making the current frontier a three-way contest between Google, Anthropic, and OpenAI. Notably, none of the top four slots are occupied by open-weights models — though open-source alternatives like DeepSeek V3.2 Speciale and Kimi K2.5 are within striking distance on many individual evaluations.
Gemini 3 Flash Preview (Reasoning) scores 46 on the Intelligence Index — well above average among reasoning models in its price tier (median: 26) — and generates output at 198.7 tokens per second, making it one of the most efficient high-intelligence options on the market.
The Omniscience Dimension: Knowledge vs. Hallucination
One of the most revealing sub-benchmarks in the Intelligence Index is AA-Omniscience , which measures not just what a model knows, but whether it knows the limits of what it knows.
Google's Gemini 3 Pro Preview leads the Omniscience Index with a score of 13, followed by Claude Opus 4.5 Thinking and Gemini 3 Flash Reasoning, both at 10. However, the breakdown between accuracy and hallucination rates reveals a more complex picture. On raw accuracy, Google's two models lead with scores of 54% and 51% respectively, but they also demonstrate higher hallucination rates of 88% and 85%. Anthropic's Claude 4.5 Sonnet Thinking and Claude Opus 4.5 Thinking show hallucination rates of 48% and 58% respectively, while GPT-5.1 with high reasoning effort achieves a hallucination rate of 51% — the second-lowest tested.
This trade-off between accuracy and hallucination is critical for production deployments. A model with high raw accuracy but high hallucination rates may confidently produce wrong answers — a more dangerous failure mode than simply refusing to answer or expressing uncertainty.
The GDPval-AA Benchmark: Testing Real Work Value
The most significant addition to the new Intelligence Index is GDPval-AA, an evaluation based on OpenAI's GDPval dataset that tests AI models on real-world economically valuable tasks across 44 occupations and 9 major industries. Unlike traditional benchmarks that ask models to solve abstract math problems or answer multiple-choice trivia, GDPval-AA measures whether AI can produce the deliverables that professionals actually create: documents, slides, diagrams, spreadsheets, and multimedia content.
This shift in evaluation philosophy is significant. For teams building AI-powered productivity tools, the ability to produce polished, professional deliverables matters far more than abstract reasoning scores. GDPval-AA is the first major benchmark that attempts to measure this directly.
Physics Frontier: CritPt Results
The results from CritPt are sobering. Current state-of-the-art models remain far from reliably solving full research-scale physics challenges. GPT-5.2 with extended reasoning leads the CritPT leaderboard with a score of just 11.5%, followed by Google's Gemini 3 Pro Preview and Anthropic's Claude 4.5 Opus Thinking. These scores serve as a useful reminder that despite remarkable progress on commercial and coding tasks, AI still has significant limitations in frontier scientific domains.
Speed: The Fastest AI Models Available
For applications where user experience depends on response velocity — chatbots, autocomplete, real-time analysis — output speed is non-negotiable. Here's how the current leaderboard breaks down:
Fastest Output Speed (Tokens Per Second)
IBM Granite 3.3 8B leads at 477 tokens per second, and Granite 4.0 H Small follows at 467 t/s — making IBM's compact Granite models the clear speed champions on the leaderboard. Gemini 2.5 Flash-Lite (Sep) and AWS Nova Micro round out the top four fastest models.
The speed hierarchy reveals a consistent trade-off: the most intelligent models (Gemini 3.1 Pro Preview, Claude Opus 4.6, GPT-5.2) generate tokens at a fraction of the speed of smaller, faster models. Choosing between intelligence and throughput remains one of the central architectural decisions in any LLM deployment.
Lowest Latency (Time to First Token)
ServiceNow's Apriel-v1.5-15B-Thinker achieves the lowest latency at just 0.18 seconds to first token, followed by NVIDIA's Llama Nemotron Super 49B v1.5 at 0.23 seconds.
Sub-0.25-second TTFT represents a meaningful user experience threshold. At these speeds, the perception of AI "thinking" essentially disappears — responses feel instantaneous. For comparison, the high-intelligence reasoning models often show TTFT in the range of 5–30+ seconds due to extended reasoning chains.
Price: The Most Cost-Effective AI Models
Cheapest Models Per Million Tokens
Google's Gemma 3n E4B is the cheapest model on the leaderboard at $0.03 per million tokens. AWS Nova Micro follows at $0.06, with NVIDIA Nemotron Nano 9B V2 and Meta's Llama 3 8B rounding out the budget tier.
To put these numbers in context: at $0.03 per million tokens, processing one million tokens costs three cents. For reference, an average novel contains roughly 100,000 words, or about 130,000 tokens — meaning you could process approximately 7.5 full novels worth of text for just one cent. These economics make very high-volume applications viable at costs that would have been inconceivable two years ago.
Understanding the Price Metric
Artificial Analysis uses a 3:1 blended ratio of input to output tokens for pricing, reflecting typical API usage patterns where prompts are often much shorter than completions. This blended rate is more useful for cost modeling than raw input or output prices, which can be misleading when compared in isolation.
For premium frontier models, pricing typically ranges from $1–$15 per million tokens on the input side and $5–$60+ per million on the output side, with reasoning models generally commanding a premium due to the additional compute involved in generating internal reasoning chains.
Context Window: Processing More Per Request
Largest Context Windows Available
Meta's Llama 4 Scout holds the record for the largest context window on the leaderboard at 10 million tokens. xAI's Grok 4.1 Fast offers the second-largest at 2 million tokens, followed by another Grok 4.1 Fast variant and Google's Gemini 2.0 Pro Experimental .
A 10-million-token context window is a staggering capability. For perspective, 10 million tokens is roughly equivalent to:
- An entire software codebase of 150,000+ lines
- Approximately 7,700 full research papers
- About 75 full-length novels read simultaneously
This scale enables entirely new application categories: comprehensive codebase analysis, multi-document synthesis, full organizational knowledge bases as system prompts, and long-horizon agent tasks that would have required chunking and retrieval in prior generations.
Context Window vs. Practical Performance
It's important to note that raw context window size and practical long-context performance are not the same thing. The Intelligence Index includes AA-LCR (Long Context Reasoning) as a specific evaluation to capture whether models actually perform well when their context is extended — not just whether they technically accept long inputs. Some models that advertise large context windows show meaningful quality degradation as context approaches their limits.
The Intelligence vs. Cost Trade-Off
Perhaps the most practically useful view in the Artificial Analysis leaderboard is the Intelligence vs. Price scatter plot, which reveals where different models sit on the efficiency frontier — defined as the models that offer maximum intelligence at any given price point.
The key takeaway from this view is that the efficiency frontier is not occupied exclusively by flagship models. Several mid-tier models offer intelligence scores that are disproportionately high relative to their cost, making them attractive for high-volume production workloads where paying frontier model prices per token would be prohibitive.
A selection of notable intelligence-to-cost relationships:
Open-Weights vs. Proprietary: Where Do They Stand?
The Artificial Analysis leaderboard distinguishes between open-weights models (where parameters are publicly available) and proprietary models (closed APIs). The intelligence gap between the two categories has narrowed substantially.
Among open-weights models, DeepSeek V3.2 Speciale , Kimi K2.5 , MiMo-V2-Flash , and GLM-5 are positioned within the upper-middle intelligence range of the overall leaderboard — below the absolute frontier proprietary models, but competitive with many mid-tier closed models.
Kimi K2 Thinking and DeepSeek V3.2 both perform well in different benchmarks, but struggle in terms of latency — a likely consequence of the fact that, being recently released, nobody has yet taken the effort to optimize them for inference performance. This is an important caveat: open-weights model performance on the leaderboard reflects their current API implementations, which may improve substantially as hosting providers apply optimization techniques like quantization, continuous batching, and speculative decoding.
How to Read the Leaderboard for Your Use Case
Different applications have fundamentally different requirements. Here's a framework for prioritizing the leaderboard dimensions by use case:
High-Intelligence Applications (Legal, Medical, Research, Complex Analysis)
Priority order: Intelligence score → Hallucination rate (AA-Omniscience) → Cost
Frontier intelligence is non-negotiable when errors carry high stakes. Prioritize models near the top of the Intelligence Index — Gemini 3.1 Pro Preview, Claude Opus 4.6 (max), GPT-5.2 (xhigh) — and pay close attention to the AA-Omniscience hallucination rate, since these applications cannot afford confidently wrong answers.
Real-Time and Interactive Applications (Chatbots, Copilots, Live Assistance)
Priority order: Latency (TTFT) → Output speed → Intelligence score → Cost
User experience is driven by perceived responsiveness. Models below 0.5 seconds TTFT with speeds above 100 t/s will feel natural in conversation. The Apriel-v1.5 line, Llama Nemotron Super 49B v1.5, and Gemini Flash variants perform well here.
High-Volume Production APIs (Content Generation, Data Processing, Classification)
Priority order: Cost per million tokens → Intelligence score (threshold) → Output speed
For high-volume workloads, cost compounds rapidly. The budget tier models (Gemma 3n E4B, Nova Micro, Nemotron Nano, Llama 3 8B) can process enormous volumes at costs that make large-scale AI economically viable. The question is whether their intelligence is sufficient for your specific task — which is best determined through direct evaluation on your workload.
Long-Document and RAG Applications (Knowledge Bases, Document Analysis, Codebase Review)
Priority order: Context window size → AA-LCR score → Intelligence score
Llama 4 Scout's 10M context window is in a category of its own for applications that require ingesting entire knowledge bases or code repositories. Grok 4.1 Fast's 2M window is the next step down. For RAG architectures that chunk and retrieve, context window becomes less critical, and intelligence + cost dominate.
Agentic and Multi-Step Workflows (Autonomous Agents, Tool Use, Orchestration)
Priority order: Agentic Index score (GDPval-AA + Terminal-Bench + τ²-Bench) → Intelligence score → Latency
Agentic tasks require a different capability profile than single-turn Q&A. The GDPval-AA, Terminal-Bench Hard, and τ²-Bench Telecom evaluations in the Intelligence Index are specifically designed to measure this. Models that excel in the overall Intelligence Index but underperform in the agentic sub-benchmarks may not be the right choice for autonomous systems.
Key Trends Visible in the 2026 Leaderboard
The intelligence gap is narrowing — but not gone. The absolute frontier (Intelligence Index score: 50+) is still occupied exclusively by proprietary models. Open-weights models are competitive in the 30–45 range but haven't broken into the top tier on the composite index.
Speed and intelligence remain in tension. The fastest models (Granite, Nova Micro, Gemini Flash-Lite) are not the most intelligent, and the most intelligent models (Gemini 3.1 Pro, Claude Opus 4.6 max) are among the slower options. A model that optimally balances both remains the dominant engineering challenge in the field.
Hallucination is the hidden performance dimension. Raw accuracy scores can be misleading if a model hallucinates frequently. The AA-Omniscience evaluation, which explicitly measures hallucination rate alongside accuracy, reveals that models with the highest raw accuracy (Google's Gemini models) are not necessarily the most reliable for factual applications.
Context windows have crossed a practical threshold. With Llama 4 Scout offering 10M tokens and multiple models now exceeding 1M, the bottleneck for many RAG and long-document applications has shifted from context window size to cost and quality at the edge of context — which is why AA-LCR (long context reasoning) has become a critical evaluation.
Pricing floors are dropping. At $0.03 per million tokens, Gemma 3n E4B represents a price point that makes AI economically viable at scales that were impractical 12 months ago. The cost of intelligence itself is declining rapidly, even as the absolute frontier continues to advance.
Final Thoughts
The Artificial Analysis LLM leaderboard is one of the most comprehensive and methodologically rigorous tools available for comparing AI models in 2026. Its combination of independently measured performance metrics, live 72-hour update cycles, and multi-dimensional evaluation framework makes it an invaluable resource for engineering teams making model selection decisions.
The core takeaway is straightforward: there is no single best model — there is the best model for your specific combination of intelligence requirements, latency tolerance, volume, and budget. Gemini 3.1 Pro Preview leads on raw intelligence. IBM Granite leads on throughput. Google Gemma leads on price. Meta Llama 4 Scout leads on context. The right choice depends entirely on where your application sits in that multi-dimensional space.
Use the leaderboard to identify the models that sit on the efficiency frontier for your specific requirements, then validate with direct evaluation on your own workloads. No benchmark fully captures the nuances of any individual application — but the Artificial Analysis Intelligence Index gets closer than most.




