The clear answer for those seeking the best balance of speed and intelligence in the current AI market is GLM-4.7, specifically its Flash variant. Developed by Zhipu AI, GLM-4.7 represents a significant leap in Large Language Model (LLM) efficiency, offering a sophisticated “thinking process” that allows the model to handle complex reasoning tasks with higher accuracy than many larger competitors. Users on platforms like Reddit's LocalLLaMA community have highlighted that the GLM-4.7-Flash model provides a remarkably logical and transparent Chain of Thought (CoT), making it an ideal choice for developers who require high-speed inference without sacrificing the quality of logical output.
Introduction to the GLM-4.7 Series
The evolution of the General Language Model (GLM) series has been a cornerstone of the open-source and enterprise AI landscape, particularly in the bilingual (Chinese and English) domain. GLM-4.7 is the latest iteration from Zhipu AI, designed to bridge the gap between “lightweight” models and “frontier” models. It is built to serve a variety of applications ranging from simple chatbots to complex autonomous agents that require deep reasoning capabilities.
What sets the 4.7 series apart is its refined training methodology. Unlike previous versions that focused heavily on raw parameter count, GLM-4.7 emphasizes “reasoning density.” This means the model is optimized to use its parameters more effectively during the inference phase, ensuring that every token generated contributes to a coherent and logically sound conclusion.
The “Flash” Revolution: High-Speed Intelligence
In the modern AI ecosystem, “Flash” models—small, fast, and cost-effective versions of larger models—are becoming the industry standard for production environments. GLM-4.7-Flash is Zhipu AI’s answer to models like GPT-4o-mini and Gemini 1.5 Flash. However, community feedback suggests that GLM-4.7-Flash holds a unique advantage in its qualitative reasoning abilities.
The Flash model is specifically optimized for low-latency tasks. In real-world testing, it demonstrates the ability to return complex answers in a fraction of the time required by full-scale models. This makes it particularly suitable for real-time applications such as live translation, interactive gaming NPCs, and immediate customer support responses where a delay of even a few seconds can degrade the user experience.
Why the “Thinking Process” Matters
One of the most discussed features of GLM-4.7-Flash on technical forums like Reddit is its “thinking process.” When prompted with complex logic puzzles or coding challenges, the model doesn't just provide a final answer; it exhibits a visible or implicit Chain of Thought (CoT) that is highly structured. This transparency allows the model to “self-correct” during the generation process, significantly reducing the likelihood of hallucinations.
A structured thinking process is vital for debugging and verification. For developers, seeing how a model arrived at a specific piece of code or a mathematical solution is often more valuable than the solution itself. GLM-4.7-Flash excels here by breaking down problems into modular steps, ensuring that each part of the reasoning chain is verified before moving to the next, which is a rare trait for a model designed for speed.
Key Technical Enhancements in GLM-4.7
The architectural improvements in GLM-4.7 are not merely incremental; they involve deep optimizations in how the model handles attention and context. These enhancements allow the model to maintain a high degree of focus even when dealing with extremely long inputs, which has historically been a weakness for smaller, faster models.
-
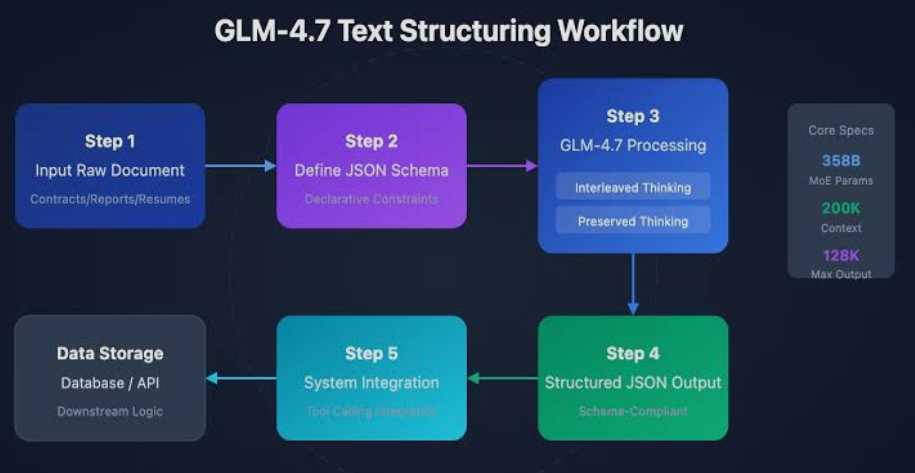
Expanded Context Window: GLM-4.7 supports massive context lengths, allowing users to input entire books, codebases, or legal documents for analysis without losing coherence.
-
Bilingual Superiority: While many Western models struggle with the nuances of Chinese syntax and culture, GLM-4.7 is natively bilingual, offering top-tier performance in both English and Chinese.
-
Reduced Inference Costs: The model is designed to be “compute-friendly,” meaning it requires less hardware power to achieve the same results as its predecessors, translating to direct cost savings for enterprises.
-
Enhanced Instruction Following: The model has been fine-tuned to follow complex, multi-step instructions with a high success rate, making it more reliable for “Agentic” workflows.
Performance Benchmarks and Real-World Testing
According to the technical data released by Zhipu AI and verified by third-party community members, GLM-4.7 shows dominant performance across several standard AI benchmarks. It particularly shines in MMLU (Massive Multitask Language Understanding) and HumanEval (coding proficiency), often rivaling models with significantly larger parameter counts.
In practical coding tests, GLM-4.7-Flash has been noted for its ability to write clean, idiomatic code in languages like Python, JavaScript, and C++. It handles edge cases and error handling more gracefully than many of its “mini” counterparts. For mathematical reasoning, the model's ability to show its work (CoT) allows it to solve multi-step word problems that typically trip up faster models that tend to “rush” to an incorrect conclusion.
Community Feedback: The LocalLLaMA Perspective
The LocalLLaMA community, a hub for enthusiasts who run AI models on personal hardware, has given GLM-4.7-Flash high marks for its accessibility and “smart” behavior. Users have reported that the model feels “heavier” in terms of intelligence than its speed would suggest, often outperforming expectations in creative writing and roleplay scenarios.
-
Logic over Speed: Users noted that while the model is fast, its priority remains on logical consistency, which prevents it from “yapping” or generating irrelevant filler text.
-
Chain of Thought Quality: The Reddit community highlighted that the model’s internal reasoning steps are often more human-like and easier to follow than those produced by OpenAI’s smaller models.
-
Hardware Compatibility: Because it is highly optimized, the Flash version can be run on modest consumer hardware, democratizing access to high-level reasoning for independent developers.
Multimodal Capabilities: Beyond Text
GLM-4.7 is not limited to text-based interactions; it is part of a broader multimodal ecosystem. Zhipu AI has integrated vision and audio capabilities into the GLM framework, allowing the model to interpret images and follow voice commands with the same level of reasoning it applies to text.
This multimodal integration is crucial for the next generation of AI applications. For instance, in an industrial setting, a GLM-4.7-powered agent could look at a photo of a broken machine, “think” through the potential mechanical failures based on its training data, and then provide a step-by-step repair guide. This “visual reasoning” is a direct extension of the text-based thinking process that has made the model so popular.
Use Cases for GLM-4.7-Flash
The versatility of GLM-4.7-Flash makes it applicable across a wide spectrum of industries. Its low cost and high reasoning power mean it can be deployed at scale without the massive overhead associated with frontier models like GPT-4o or Claude 3.5 Sonnet.
-
Customer Service Agents: Capable of handling complex queries that require checking multiple databases and following logical protocols.
-
Educational Tutors: Its transparent “thinking process” makes it an excellent tool for teaching students how to solve math or logic problems.
-
Coding Assistants: Ideal for real-time autocomplete and code refactoring where speed is essential for developer flow.
-
Data Analysis: Can ingest large CSV or JSON files and provide reasoned summaries and trend analysis within seconds.
How to Access and Deploy GLM-4.7
Zhipu AI provides multiple pathways for accessing GLM-4.7, catering to both individual developers and large-scale enterprises. The model is available through the BigModel API, which offers a robust and scalable environment for those who prefer managed services.
For those who prioritize privacy or want to avoid latency associated with cloud API calls, the GLM models are frequently released with open-weights or available through platforms that support local deployment. This allows teams to host the model on their own infrastructure, ensuring that sensitive data never leaves their local environment. The high efficiency of the Flash model ensures that even on-premise deployments are cost-effective in terms of energy and hardware maintenance.
Comparing GLM-4.7-Flash to Competitors
When placed side-by-side with other “Flash” or “Mini” models, GLM-4.7-Flash holds a distinct position. While models like GPT-4o-mini are incredibly fast and broadly capable, GLM-4.7-Flash is often cited as having a “deeper” feel to its responses, particularly in technical and bilingual contexts.
One area where GLM-4.7-Flash excels is in its refusal to sacrifice detail for the sake of brevity. Some small models are tuned to be as concise as possible, which can lead to the omission of critical nuances. GLM-4.7 maintains a balance, providing a complete “thinking” trace that ensures the user understands the “why” behind the “what.” This makes it a superior choice for professional environments where accuracy and auditability are non-negotiable.
The Future of the GLM Ecosystem
The release of GLM-4.7 is a strong signal that the future of AI lies in “efficiency-first” design. Zhipu AI continues to iterate on the GLM architecture, with plans to further integrate reasoning capabilities into even smaller models. This trend suggests a world where high-level intelligence can run on everything from mobile phones to low-power IoT devices.
As the “thinking process” of models like GLM-4.7-Flash becomes even more refined, we expect to see a shift in how humans interact with AI. Instead of seeing the model as a simple answer-machine, users will treat it as a collaborative partner that can think through problems alongside them. The transparency provided by the 4.7 series is the first major step toward building the trust required for that level of collaboration.
Summary of Benefits for Developers
For developers looking to integrate AI into their workflows, GLM-4.7-Flash offers a unique set of advantages that are hard to find in other models currently on the market.
-
Logic Accuracy: Best-in-class reasoning for a “Flash” category model.
-
Bilingual Efficiency: Unmatched performance for projects requiring both English and Chinese support.
-
Transparency: A visible and logical Chain of Thought that helps in debugging and user trust.
-
Scalability: Low API costs and high speed make it suitable for massive user bases.
-
Context Support: Ability to process long-form data without losing the context of the initial prompt.
Conclusion: Why GLM-4.7 is a Must-Try
In conclusion, GLM-4.7 and its Flash variant represent a significant milestone in the democratisation of high-level AI reasoning. By focusing on the “thinking process” rather than just the final output, Zhipu AI has created a model that is not only fast but also deeply logical and reliable. Whether you are a developer looking for a cost-effective coding assistant or an enterprise building complex automated agents, GLM-4.7-Flash provides the performance and transparency needed to succeed in an increasingly competitive AI landscape.
The enthusiastic reception from the LocalLLaMA community further validates that this model is not just a marketing claim but a practical, high-performance tool that stands up to real-world scrutiny. If you value a model that can “think” before it speaks, GLM-4.7-Flash is currently one of the strongest contenders in the global market.