
| Model Version | Inference Speed | Detection Accuracy | Object Size Sensitivity |
|---|---|---|---|
| YOLOv5 | High | Moderate | 1%, 2.5%, 5% |
| YOLOv8 | Very High | High | 1%, 2.5%, 5% |
| YOLOv9 | Moderate | High | 1%, 2.5%, 5% |
| YOLOv10 | High | Very High | 1%, 2.5%, 5% |
| YOLOv11 | Very High | Very High | 1%, 2.5%, 5% |

Image recognition has become a driving force behind artificial intelligence in 2025. It allows machines to analyze and interpret visual data with extraordinary accuracy. This capability has sparked significant advancements in industries like healthcare and autonomous vehicles.
- The image recognition market is projected to grow from $53.4 billion in 2024 to $61.97 billion in 2025 , reflecting a compound annual growth rate (CAGR) of 16.1%.
- For autonomous vehicles, the computer vision market is expected to reach $55.67 billion by 2026 , with a staggering CAGR of 39.47%.
These numbers highlight the growing importance of image recognition technology. By combining computer vision with innovative algorithms, this technology is reshaping diagnostics, transportation, and urban infrastructure. Its integration into real-time analytics and self-supervised learning is also improving efficiency and scalability across industries.
Key Takeaways
- Image recognition is growing fast and could be worth $61.97 billion by 2025. It is becoming more important in many industries.
- Convolutional Neural Networks (CNNs) help computers recognize images. They let systems find and sort objects by studying pictures.
- AI image recognition helps doctors find diseases faster, like cancer. It uses advanced tools to make diagnoses more accurate.
- Self-driving cars use object detection to drive safely. They understand their surroundings and avoid obstacles quickly.
- Fixing privacy and bias issues in AI is very important. It builds trust and makes sure results are fair, needing clear and ethical rules.
How Image Recognition Works
Neural Networks and Image Processing
Neural networks form the backbone of modern image recognition systems. These networks mimic the human brain's ability to process visual data by identifying patterns and features in images. When you upload an image, the system breaks it down into pixels and analyzes the color, texture, and intensity of each pixel. This process enables the network to recognize objects, shapes, and even emotions in the image.
Deep learning techniques, such as convolutional neural networks (CNNs), have revolutionized how image recognition works. These networks excel at extracting features like edges, lines, and curves, which are essential for identifying objects. For example, CNNs can distinguish between a cat and a dog by analyzing the unique features of their fur patterns and facial structures. This capability has made CNNs a cornerstone of computer vision technology.
Neural networks also play a crucial role in object localization and object segmentation. Localization involves identifying the exact position of an object within an image, while segmentation divides the image into meaningful regions. These processes are vital for applications like autonomous vehicles, where precise object detection ensures safety and efficiency.
Convolutional Neural Networks (CNNs) in Feature Extraction
Convolutional neural networks are at the heart of image recognition systems. They use layers of filters to scan images and extract features that help classify and identify objects. Each layer focuses on a specific aspect of the image, such as edges, textures, or colors. This hierarchical approach allows CNNs to build a detailed understanding of the image.
For instance, CNNs have been instrumental in advancing image classification tasks. They can categorize images into thousands of classes with remarkable accuracy. A study demonstrated that CNNs could classify phenological data from community science images, showcasing their effectiveness in real-world applications. Additionally, CNNs are widely used in object localization, enabling systems to pinpoint objects within an image accurately.
Modern CNN architectures, such as YOLO (You Only Look Once) and Vision Transformers (ViT), have further enhanced the capabilities of image recognition systems. YOLO divides an image into a grid and predicts bounding boxes and class probabilities for each grid cell, enabling real-time object detection. ViT, on the other hand, applies transformers to image classification by dividing images into patches and processing them through transformer layers. These advancements have made CNNs indispensable for tasks like predictive maintenance and quality inspection.
Data Training and Labeling in AI Image Recognition
Training models for image recognition requires large datasets of labeled images. These datasets serve as the foundation for teaching the system to recognize and classify objects. For example, the ImageNet dataset has been pivotal in advancing deep learning algorithms by challenging systems to identify thousands of object categories.
The process of model training involves feeding the system with labeled images and adjusting its parameters to minimize errors. This iterative process ensures that the model learns to generalize from the training data and perform well on new, unseen images. Effective data training and labeling are crucial for improving the accuracy and reliability of AI image recognition systems.
Image annotation services play a significant role in this process. They provide the labeled data needed for training models, enabling systems to identify objects with high precision. Research has shown that competence-based active learning approaches can significantly enhance image classification accuracy. By selecting the most informative samples for labeling, these methods optimize the training process and improve the performance of deep learning models.
In 2025, advancements in data training and labeling continue to drive innovation in image recognition. From healthcare diagnostics to agricultural applications, well-trained models are transforming industries and solving complex problems.
Key Algorithms in AI Image Recognition
Convolutional Neural Networks (CNNs): The Backbone of Computer Vision
Convolutional neural networks (CNNs) are the foundation of modern image recognition systems. They excel at analyzing visual data by breaking images into smaller parts and identifying patterns. You can think of CNNs as specialized tools that focus on features like edges, textures, and colors to classify and recognize objects.
Several factors validate CNNs as the dominant algorithm in computer vision tasks:
- Large Data Set : Models like AlexNet were trained on over 1.2 million images , enabling them to learn diverse features.
- Deep Architecture : With eight layers, AlexNet could capture complex hierarchical representations.
- Convolutional Layers : These layers extract spatially invariant features critical for classification.
- ReLU Activation : This function speeds up learning and prevents issues like vanishing gradients.
- Data Augmentation : Techniques like cropping and flipping expand training datasets, reducing overfitting.
- Dropout Regularization : Randomly dropping neurons during training improves generalization.
CNNs have proven their effectiveness in tasks like object recognition and neural networks in image matching. For example, studies comparing CNN architectures like ResNet18 and VGG16 show their ability to classify medical images with high accuracy. These algorithms continue to evolve, making them indispensable for applications like healthcare diagnostics and autonomous navigation.
YOLO (You Only Look Once): Real-Time Object Detection
YOLO, short for "You Only Look Once," revolutionizes real-time object detection by processing images in a single pass. Unlike traditional methods that analyze images multiple times, YOLO divides an image into a grid and predicts bounding boxes and class probabilities simultaneously. This approach makes YOLO incredibly fast and efficient.
Recent advancements in YOLO models, such as YOLO11, have significantly improved accuracy. Features like C2PSA and two kernel convolutions enhance feature extraction across multiple scales, enabling better detection of objects with varying sizes and complexities.
You’ll find YOLO applied in diverse fields, including advanced driver-assist systems, video surveillance, and healthcare . For instance, YOLO’s ability to detect cancerous cells in medical imaging highlights its transformative impact on diagnostics. Its speed and accuracy make it a preferred choice for large-scale AI applications.
Vision Transformers: Transforming How Image Recognition Works
Vision Transformers (ViTs) represent a paradigm shift in image recognition. Unlike CNNs, which rely on convolutional layers, ViTs use transformer architectures to process images. They divide images into patches and analyze them through attention mechanisms, enabling the model to focus on the most relevant features.
Research shows that ViTs outperform traditional CNNs in several benchmarks. The paper “An Image is Worth 16×16 Words” by Dosovitskiy et al. demonstrates how ViTs achieve superior accuracy while requiring fewer computational resources. Their scalability makes them ideal for tasks ranging from face recognition to object detection.
ViTs also offer advantages like robustness against occlusions and a smaller memory footprint. These qualities make them highly efficient for real-time applications. As you explore the future of AI image recognition, you’ll see ViTs becoming a preferred choice due to their ability to balance performance and resource efficiency.
Applications of Image Recognition in 2025

Healthcare: Revolutionizing Diagnostics and Medical Imaging
Image recognition technology is transforming healthcare by enhancing diagnostic accuracy and streamlining medical imaging processes. AI-powered systems analyze complex medical images like MRI scans and CT scans, identifying abnormalities with precision. For example, deep learning models such as nnU-Net have demonstrated exceptional performance in detecting prostate cancer, achieving a 92% accuracy rate . These advancements improve treatment planning and patient outcomes.
AI image recognition also supports automated segmentation, which divides medical images into meaningful regions. This process helps radiologists focus on critical areas, reducing workload and improving efficiency. Studies show that AI-assisted imaging enhances diagnostic accuracy across modalities, including ultrasonography. However, researchers emphasize the need for larger datasets and validation procedures to ensure reliability in clinical practice.
| Key Findings | Implications |
|---|---|
| AI-assisted imaging improves diagnostic accuracy across MRI, CT, and ultrasonography . | Enhances precision in clinical settings, leading to better patient outcomes. |
| Limited studies on oral mucosal lesions highlight research gaps. | Calls for more comprehensive datasets and validation studies. |
Autonomous Vehicles: Enhancing Navigation and Safety
Image recognition applications in autonomous vehicles are revolutionizing navigation and safety. By enabling real-time object detection , these systems allow vehicles to interpret their surroundings effectively. For instance, image detection technology identifies traffic signs, pedestrians, and other vehicles, ensuring safe and efficient driving.
The integration of computer vision in autonomous systems enhances decision-making capabilities. Vehicles equipped with AI image recognition can quickly respond to sudden situations, such as unexpected obstacles. This rapid reaction reduces the likelihood of accidents and improves overall reliability. Additionally, these systems provide passengers with an intuitive understanding of the vehicle’s state and route, fostering trust in autonomous transportation.
| Improvement Aspect | Description |
|---|---|
| Real-time Object Recognition | Recognizes external environmental objects and traffic conditions during driving. |
| Quick Response to Sudden Situations | Reacts rapidly to unexpected events in the driving environment. |
| Enhanced Passenger Understanding | Offers an intuitive depiction of the vehicle’s state and route. |
| Overall Safety and Reliability | Provides a safer and more reliable driving experience. |
Security: Facial Recognition and Threat Detection
Facial recognition systems are redefining security by enabling accurate identification of individuals and potential threats. These systems use advanced image classification techniques to analyze facial features, even under challenging conditions like poor lighting or camera angles. Forensic facial comparison studies highlight their effectiveness in controlled environments, though real-world applications face limitations due to image quality factors.
Image recognition technology plays a crucial role in surveillance and threat detection. It identifies suspicious activities and individuals, helping security teams respond proactively. However, researchers recommend isolating specific limiting factors, such as distortions, to improve accuracy in diverse scenarios. As these systems evolve, they promise to enhance public safety and streamline security operations.
| Evidence Summary | Details |
|---|---|
| Study Focus | Forensic facial comparison and limitations of automated systems. |
| Conditions Tested | Ideal photographic images, CCTV setups, and disguises. |
| Key Findings | High accuracy in controlled conditions but limitations in real-world applications . |
| Recommendations | Future studies should address specific limiting factors to improve accuracy. |
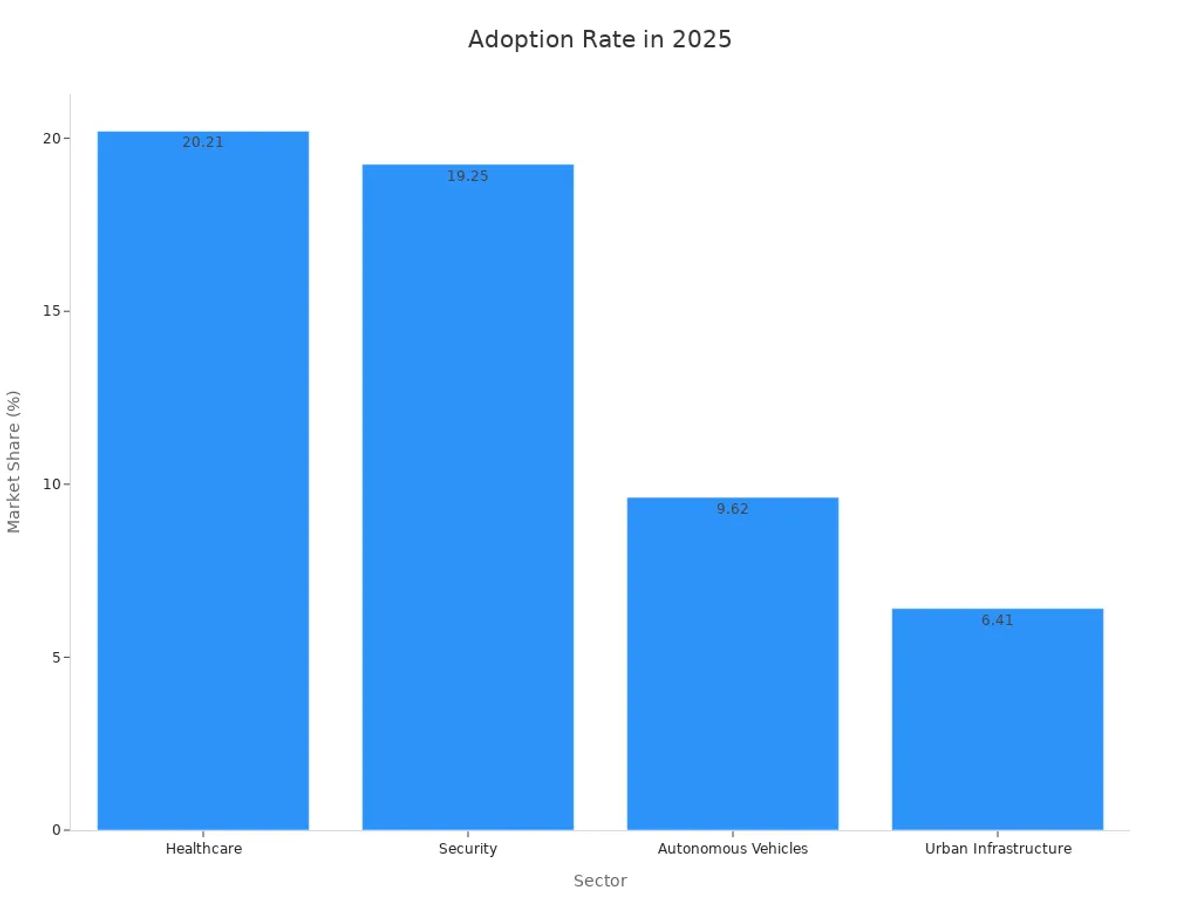
Smart Cities: Optimizing Urban Infrastructure with Computer Vision
In 2025, computer vision is transforming how cities operate, making them smarter and more efficient. By using image recognition, urban planners can analyze visual data to optimize infrastructure and improve the quality of life for residents. You can see its impact in various areas, from traffic management to public safety.
Traffic management systems now rely on computer vision to monitor and control congestion. Cameras equipped with advanced algorithms detect traffic patterns and adjust signals in real time. This reduces delays and ensures smoother commutes. Air quality monitoring has also improved. Smart sensors and cameras analyze pollution levels, helping cities implement targeted measures to reduce emissions.
Public safety has seen significant advancements. Image recognition systems enhance surveillance by identifying potential threats and alerting authorities. Automated Number Plate Recognition (ANPR) technology tracks vehicles, aiding in crime prevention and traffic enforcement. Parking management has become more efficient as well. Smart cameras guide drivers to available spaces, saving time and reducing frustration.
Computer vision also addresses infrastructure maintenance. For example, pothole detection systems use cameras to identify road damage, enabling timely repairs. Crowd management in public spaces has improved too. These systems monitor gatherings, ensuring safety during events or emergencies.
The effectiveness of these applications depends on robust algorithms. Bayesian Regularized neural networks, for instance, have demonstrated exceptional accuracy in urban infrastructure tasks. With a low error value of 0.00023034 after 167 training epochs , these models excel at processing complex data. This precision ensures reliable solutions for urban challenges.
As cities continue to grow, computer vision will play an even greater role in shaping their future. By leveraging this technology, you can create smarter, safer, and more sustainable urban environments.
Challenges and Future Trends in Image Recognition
Addressing Data Privacy and Ethical Concerns
Data privacy remains a critical challenge in image recognition. Many systems collect sensitive information, such as personal identifiable information (PII) and biometrics, raising concerns about misuse. For example, facial recognition technologies often scrape images from public sources without consent . This practice highlights the need for stricter regulations and ethical guidelines.
A study emphasizes that companies like Clearview AI do not seek permission to collect images, leading to significant privacy concerns. It calls for transparency, accountability, and federal privacy legislation to protect individuals, particularly vulnerable communities, from surveillance.
High-profile data breaches further expose vulnerabilities in AI systems. A 2021 incident compromised millions of personal health records , underscoring the need for robust safeguards. Regulatory frameworks, such as the EU's AI Act, aim to address these issues by enforcing stricter compliance and minimizing data collection.
| Key Challenges | Description |
|---|---|
| Collection of Sensitive Data | AI systems often gather PII and biometrics , raising ethical and privacy concerns. |
| Regulatory Compliance | Companies must adhere to privacy laws like SEC Regulation S-P. |
| Algorithmic Transparency | Ensuring AI systems are transparent and comply with privacy standards. |
Combating Bias in AI Image Recognition Models
Bias in image recognition systems can lead to unfair outcomes. Non-diverse datasets, such as ImageNet, often over-represent certain demographics, resulting in representation bias. This issue becomes evident in applications like facial recognition, where models may perform poorly on underrepresented groups.
- Historical bias reflects societal inequalities embedded in training data.
- Representation bias arises from datasets that lack diversity.
- Algorithmic bias stems from flaws in the AI's design, independent of input data.
To mitigate bias, you can adopt strategies like diversifying datasets, implementing fairness metrics, and conducting regular audits. These measures ensure that AI systems perform equitably across all demographics.
Emerging Trends: Edge AI and Advanced Transformers
Edge AI is revolutionizing image recognition by enabling real-time processing on devices like smartphones and IoT sensors. This approach reduces latency and enhances privacy by processing data locally. Specialized AI hardware, such as energy-efficient processors, further optimizes edge devices for complex tasks like segmentation.
| Trend/Benchmark | Description |
|---|---|
| Dominance in Edge AI Market | Video and image recognition lead in security systems and real-time detection. |
| Growth Drivers | IoT adoption, 5G expansion, and demand for real-time decision-making. |
| Specialized AI Hardware | Energy-efficient processors enhance edge devices' capabilities. |
Advanced transformers, such as Vision Transformers (ViTs), are also shaping the future of image recognition. These models divide images into patches and process them through attention mechanisms, offering superior accuracy and efficiency. Their scalability makes them ideal for applications like segmentation and object detection.
Quantum Computing and the Future of Image Recognition
Quantum computing is reshaping the landscape of image recognition. Unlike classical computers, quantum systems process data using quantum bits (qubits). These qubits can exist in multiple states simultaneously, enabling faster and more complex computations. You can think of quantum computing as a tool that unlocks new possibilities for solving problems that traditional systems struggle to handle.
How Quantum Computing Enhances Image Recognition
Quantum computing accelerates image recognition tasks by processing vast amounts of data in parallel. This capability improves the speed and accuracy of algorithms used for tasks like object detection and image classification. For example, quantum algorithms can analyze high-resolution medical images more efficiently, helping doctors identify abnormalities faster.
Tip : Quantum computing excels at handling large datasets, making it ideal for applications like satellite imagery analysis and climate monitoring.
Key Benefits of Quantum Computing in Image Recognition
- Improved Accuracy : Quantum systems reduce errors in complex image recognition tasks.
- Faster Processing : They handle computations at speeds unattainable by classical computers.
- Enhanced Scalability : Quantum algorithms scale effectively with increasing data complexity.
| Feature | Classical Computing | Quantum Computing |
|---|---|---|
| Processing Speed | Limited | Extremely Fast |
| Data Handling | Sequential | Parallel |
| Scalability | Moderate | High |
Real-World Applications
Quantum computing is transforming industries. In healthcare, it enables precise analysis of medical scans. In security, it enhances facial recognition systems by improving accuracy under challenging conditions. Autonomous vehicles benefit from quantum-powered image recognition, which processes environmental data in real time to ensure safety.
As quantum computing evolves, you’ll see it driving innovation in image recognition. Its ability to solve complex problems quickly makes it a cornerstone of future AI applications.
Image recognition stands as a cornerstone of modern AI, enabling machines to analyze visual data with unmatched precision. In 2025, you see its applications reshaping industries, from healthcare to urban infrastructure. Emerging technologies like edge AI and quantum computing promise even greater advancements, ensuring faster and more efficient solutions.
To overcome challenges like privacy and bias, you can focus on:
- Prioritizing privacy and ethical considerations in AI systems .
- Implementing robust data security measures to protect individual privacy.
- Advocating for transparency and accountability to build trust with stakeholders.
These efforts ensure a future where image recognition continues to drive innovation while addressing critical concerns.
FAQ
What is the difference between image recognition and computer vision?
Image recognition focuses on identifying objects, patterns, or features in images. Computer vision goes beyond recognition, enabling machines to interpret and analyze visual data for tasks like object tracking, segmentation, and scene understanding. You can think of image recognition as a subset of computer vision.
How does image recognition improve healthcare diagnostics?
Image recognition analyzes medical images like X-rays or MRIs to detect abnormalities. AI models identify patterns that might be missed by the human eye. For example, systems can pinpoint early signs of cancer, helping doctors make faster and more accurate diagnoses.
Can image recognition work without large datasets?
Yes, but performance may suffer. Large datasets improve accuracy by exposing models to diverse scenarios. Techniques like transfer learning and synthetic data generation help when datasets are limited. These methods allow you to train models effectively with fewer labeled images.
Is image recognition technology biased?
Bias can occur if training datasets lack diversity. For example, facial recognition systems may perform poorly on underrepresented groups. You can reduce bias by using diverse datasets, applying fairness metrics, and auditing models regularly to ensure equitable performance.
What industries benefit the most from image recognition?
Healthcare, security, transportation, and smart cities gain the most. In healthcare, it enhances diagnostics. Security systems use it for facial recognition and threat detection. Autonomous vehicles rely on it for navigation, while smart cities optimize traffic and infrastructure using image recognition.



