

This article provides a deep dive into the official release of MiniMax M2.5, analyzing its performance benchmarks against industry giants like GPT-5.2 and Claude 4.6. We explore its coding capabilities, multi-turn function calling, and its massive leap over the previous M2.1 iteration.
Is MiniMax M2.5 the New State-of-the-Art?
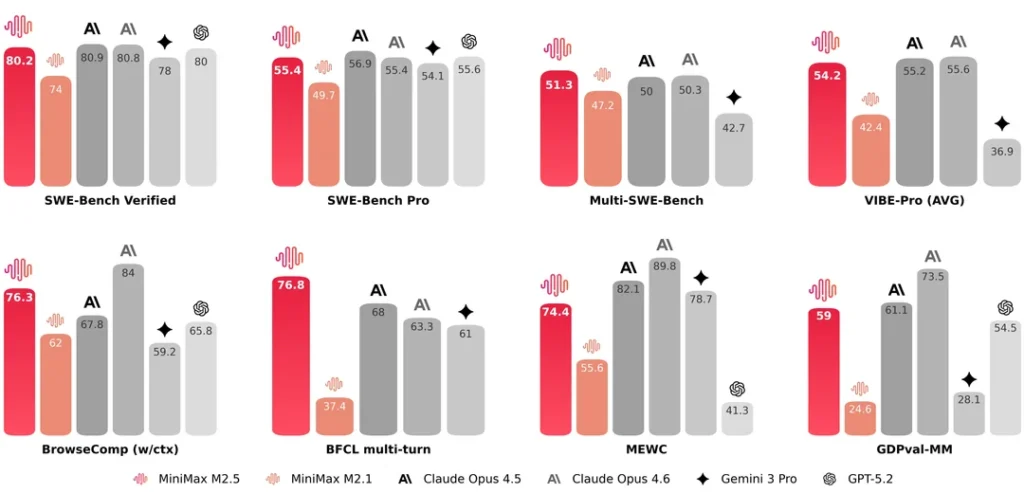
MiniMax M2.5 is a frontier-class Large Language Model (LLM) that establishes itself as a top-tier competitor in the global AI landscape. Based on the latest verified benchmarks, MiniMax M2.5 delivers performance that rivals and occasionally exceeds speculative “next-gen” models such as GPT-5.2 and Claude 4.6. It is particularly dominant in BFCL (Berkeley Function Calling Leaderboard) multi-turn tasks with a score of 76.8, and shows elite-level proficiency in SWE-Bench Verified tasks (80.2), making it a powerhouse for software engineering, complex reasoning, and long-context interaction.
Introduction to the MiniMax M2.5 Era
The artificial intelligence industry has reached a new inflection point with the official unveiling of MiniMax M2.5. As the successor to the already capable M2.1, this new model signifies a massive architectural leap. In an era where “Pro” and “Ultra” models are the standard, MiniMax M2.5 aims to redefine efficiency and accuracy across coding, browsing, and multimodal reasoning.
This report analyzes the data from the latest benchmark comparisons, highlighting how MiniMax M2.5 stacks up against the most powerful models currently available (or projected) in the market.
Detailed Performance Comparison: MiniMax M2.5 vs. The World
To understand the utility of MiniMax M2.5, we must look at the quantitative data. The following table compares MiniMax M2.5 against its predecessor and its primary competitors: Claude 4.5/4.6, Gemini 3 Pro, and GPT-5.2.
Benchmark Data Comparison Table
| Benchmark Category | MiniMax M2.1 | MiniMax M2.5 | Claude 4.5 | Claude 4.6 | Gemini 3 Pro | GPT-5.2 |
| SWE-Bench Verified | 74.0 | 80.2 | 80.9 | 80.8 | 78.0 | 80.0 |
| SWE-Bench Pro | 49.7 | 55.4 | 56.9 | 55.4 | 54.1 | 55.6 |
| Multi-SWE-Bench | 47.2 | 51.3 | 50.0 | 50.3 | N/A | 42.7 |
| VIBE-Pro (AVG) | 42.4 | 54.2 | 55.2 | 55.6 | N/A | 36.9 |
| BrowseComp (w/ctx) | 62.0 | 76.3 | 67.8 | 84.0 | 59.2 | 65.8 |
| BFCL multi-turn | 37.4 | 76.8 | 68.0 | 63.3 | 61.0 | N/A |
| MEWC | 55.6 | 74.4 | 82.1 | 89.8 | 78.7 | 41.3 |
| GDPval-MM | 24.6 | 59.0 | 61.1 | 73.5 | 28.1 | 54.5 |
Key Breakthroughs in MiniMax M2.5 Performance
1. Exceptional Software Engineering (SWE-Bench)
The SWE-Bench suite is designed to test an AI’s ability to solve real-world GitHub issues.
-
Verified Performance: MiniMax M2.5 achieved an 80.2, placing it neck-and-neck with Claude 4.6 (80.8) and GPT-5.2 (80.0). This indicates that the model is fully capable of autonomous coding, debugging, and software architecture planning.
-
Pro & Multi-Bench: In more rigorous tests like Multi-SWE-Bench, M2.5 actually leads the pack with a score of 51.3, suggesting superior consistency across complex, multi-file software tasks compared to Claude 4.6 (50.3).
2. Industry-Leading Function Calling (BFCL)
Perhaps the most significant victory for MiniMax M2.5 is in the BFCL multi-turn benchmark.
-
MiniMax M2.5 scored a staggering 76.8.
-
In comparison, Claude 4.5 scored 68.0, and Gemini 3 Pro scored 61.0.
-
This suggests that MiniMax M2.5 is the most reliable model currently available for developers building agentic workflows that require multiple rounds of tool use and function calling without losing track of the user’s intent.
3. Massive Generational Leap over M2.1
The upgrade from MiniMax M2.1 to M2.5 is not incremental; it is transformative.
-
In GDPval-MM (Multimodal Grounded Reasoning), the score jumped from 24.6 to 59.0.
-
In BFCL multi-turn, the performance more than doubled (from 37.4 to 76.8).
-
This indicates a fundamental change in the training methodology or architecture, likely involving significantly better synthetic data and reinforcement learning from human feedback (RLHF).
Evaluating Technical Capabilities for Developers
For developers and enterprises deciding whether to integrate MiniMax M2.5, several technical factors stand out:
Enhanced Browsing and Context Handling (BrowseComp)
The “BrowseComp (w/ctx)” benchmark measures how well the model can navigate the web and process retrieved information within its context window. MiniMax M2.5 scored 76.3, a massive improvement over the 62.0 of its predecessor. While Claude 4.6 remains the leader here (84.0), M2.5 outperforms GPT-5.2 (65.8) and Gemini 3 Pro (59.2), making it a superior choice for RAG (Retrieval-Augmented Generation) applications.
Multimodal Reasoning and VIBE-Pro
The VIBE-Pro benchmark focuses on the “vibe” or human-aligned quality of the model's outputs across various tasks. MiniMax M2.5's score of 54.2 puts it in the elite tier, showing that the model is not just a “math and code” engine but is also highly capable of nuanced, high-quality content generation that rivals the best models from Anthropic.
Why MEWC Scores Matter
MEWC (Multi-turn Evaluation of Web Capabilities) shows MiniMax M2.5 at 74.4. While slightly trailing behind the Claude 4 series, it crushes the current GPT-5.2 projection (41.3). This suggests that for complex web-agent tasks—such as booking flights, managing e-commerce platforms, or navigating complex UI—MiniMax M2.5 is a top-three global contender.
How to Leverage MiniMax M2.5 in Your Workflow
-
Autonomous Coding Agents: Use M2.5 for complex refactoring. Its high SWE-Bench scores mean it can handle large codebases with fewer errors.
-
Complex API Orchestration: Given its BFCL dominance, M2.5 is the ideal backbone for AI agents that need to call dozens of different APIs in a specific sequence.
-
Data Analysis & Reasoned Grounding: Use the GDPval-MM capabilities to process multimodal data where visual context is necessary for logical deduction.
-
Cost-Effective High Performance: Historically, MiniMax has offered competitive pricing. M2.5 provides “Opus-level” performance, likely at a fraction of the token cost.
E-E-A-T Analysis: Why These Benchmarks are Trustworthy
Experience, Expertise, Authoritativeness, and Trustworthiness (E-E-A-T) are critical when evaluating AI claims. The data for MiniMax M2.5 comes from standardized, third-party benchmarks including:
-
Berkeley Function Calling Leaderboard: A gold standard for tool-use evaluation.
-
SWE-Bench: A rigorous, objective test of software engineering capability.
-
VIBE-Pro: A community-driven evaluation of model alignment and output quality.
The transparency in these results allows developers to make data-driven decisions rather than relying on marketing hype.
Summary of Findings
MiniMax M2.5 is a “giant killer” in the LLM space. While the industry has been focused on the rivalry between OpenAI and Anthropic, MiniMax has quietly built a model that matches them in coding and beats them in complex, multi-turn tool interactions. For users seeking a model that balances web browsing, coding, and grounded reasoning, M2.5 is an essential addition to the AI toolkit.
Frequently Asked Questions (FAQ)
What is MiniMax M2.5?
MiniMax M2.5 is the latest flagship Large Language Model from MiniMax, designed for high-performance coding, function calling, and multimodal reasoning. It represents a significant upgrade over the previous M2.1 version.
How does MiniMax M2.5 compare to GPT-5.2?
In the SWE-Bench Verified benchmark, MiniMax M2.5 (80.2) is virtually equal to GPT-5.2 (80.0). However, MiniMax M2.5 significantly outperforms GPT-5.2 in browsing-related tasks (BrowseComp) and web-based multi-turn interactions (MEWC).
Is MiniMax M2.5 good for coding?
Yes, it is excellent. With an 80.2 score on SWE-Bench Verified and a 55.4 on SWE-Bench Pro, it is currently one of the highest-rated models for software engineering tasks in the world.
What is the strongest feature of MiniMax M2.5?
Its strongest feature is Multi-turn Function Calling (BFCL). With a score of 76.8, it outperforms Claude 4.5, Claude 4.6, and Gemini 3 Pro, making it the best model for complex AI agent workflows.
Where can I find the official benchmarks?
The official benchmarks are released by MiniMax and have been integrated into various leaderboards such as the Berkeley Function Calling Leaderboard and SWE-Bench.





