


Image segmentation stands at the center of breakthroughs in AI and robotics for 2024-2025. This technology powers intelligent perception and guides decision-making in fields such as healthcare and automation.
-
Recent studies show deep learning and transformer models boost image segmentation accuracy, especially in medical and clinical tasks.
-
Semantic segmentation now supports precise cell classification, while advances in computer vision help robots understand their surroundings.
|
Year |
|
|---|---|
|
2022 |
Computer vision and sensor fusion improve robotics. |
|
2023 |
AI-powered service robotics expands rapidly. |
These advancements drive real-world change and promise even more innovation ahead.
Key Takeaways
-
Deep learning and vision transformers have greatly improved image segmentation accuracy and speed, enabling better object detection in healthcare and robotics.
-
Edge AI and real-time video analysis allow devices and robots to process images quickly on-site, reducing delays and improving responsiveness.
-
Advances in annotation methods and weakly supervised learning reduce manual work and increase efficiency in building segmentation datasets.
-
Challenges like noisy data annotation, high computational demands, and domain adaptation remain, requiring ongoing research and better tools.
-
Future growth in AI and robotics depends on lightweight models, multi-modal data, and collaboration to create smarter, faster, and more reliable segmentation systems.
Segmentation Techniques
The field of image segmentation has experienced rapid transformation, especially during 2024-2025. Researchers and engineers have moved from classical algorithms to advanced deep learning models, enabling machines to see and understand the world with greater accuracy. These advancements have shaped the way computer vision systems perform object detection and scene analysis in robotics and AI.
Deep Learning Models
Deep learning models have become the backbone of modern image segmentation. Early methods relied on manual techniques like thresholding, clustering, and edge detection. These classical approaches struggled with complex scenes and required significant manual feature engineering. The introduction of convolutional neural networks (CNNs) marked a turning point. AlexNet, launched in 2012, demonstrated the power of deep learning for image classification, paving the way for more sophisticated segmentation techniques.
Deep learning models such as U-Net and DeepLab have revolutionized computer vision by learning hierarchical features and contextual information. These models deliver faster inference and improved segmentation performance compared to classical methods. They also use architectural features like skip connections and attention mechanisms, which help the model focus on important regions in an image.
Recent comparative studies show that deep learning models outperform classical methods in both accuracy and speed. For example, the BraTS challenge benchmarked deep learning for brain tumor segmentation, revealing superior results. In medical imaging, deep learning models have improved automation and accuracy, supporting early diagnosis and treatment planning.
The table below highlights benchmark metrics for several deep learning models used in image segmentation:
|
Model |
Precision |
Recall |
F1-score |
IOU |
|---|---|---|---|---|
|
DenseNet-121 |
0.794-0.870 |
0.920 |
0.920 |
0.870 |
|
Efficient-Net |
0.912 |
0.982 |
0.903-0.981 |
0.870 |
|
ResNet-50 |
– |
– |
0.931 |
0.870 |
These results demonstrate the effectiveness of deep learning models in computer vision tasks, especially for object detection and segmentation.
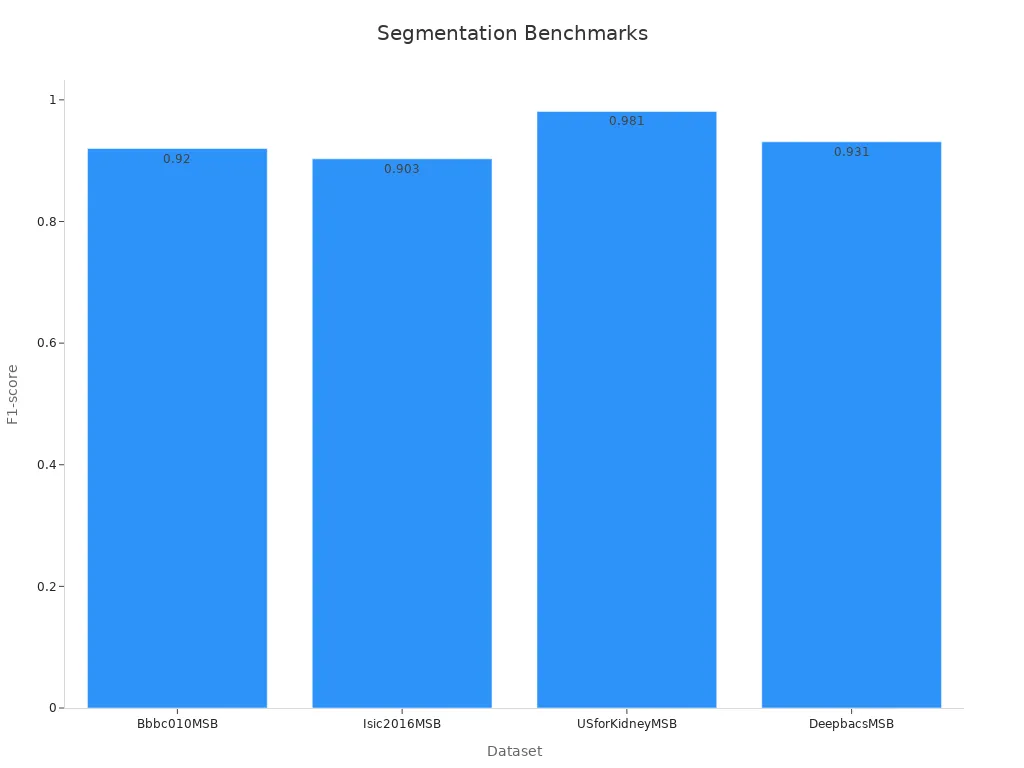
Vision Transformers
Vision transformers (ViTs) have emerged as a powerful tool for image segmentation in 2024-2025. Unlike traditional CNNs, vision transformers use self-attention mechanisms to process entire images as sequences of patches. This approach allows the model to capture long-range dependencies and global context, which is essential for accurate object detection and segmentation.
Recent work presented at CVPR 2024 introduced data-adaptive modifications to vision transformers, addressing their lack of shift-equivariance. These enhancements, applied to models like Swin, SwinV2, CvT, and MViTv2, resulted in perfect circular shift-equivariance and improved robustness to spatial shifts. The improved models achieved competitive semantic segmentation performance across diverse datasets, ensuring more consistent and reliable results.
Vision transformers now deliver spatially consistent and robust segmentation, making them ideal for applications in robotics and computer vision where precise object detection is critical.
Fully Convolutional Networks
Fully convolutional networks (FCNs) have played a key role in advancing image segmentation. Introduced in 2015, FCNs replaced fully connected layers with convolutional layers, enabling pixel-wise predictions and detailed spatial outputs. This innovation allowed computer vision systems to perform semantic segmentation with greater accuracy.
Comparative performance studies have shown that FCNs and their variants outperform classical algorithms in both accuracy and computational efficiency. For example, CNN-LSTM models surpass support vector machines (SVMs) and standalone CNNs in texture classification tasks. Self-distillation techniques further boost accuracy, with improvements ranging from 0.61% to 4.07% across different neural network architectures.
|
Study/Methodology |
Statistical Evidence |
Performance Improvement Details |
|---|---|---|
|
CNN + kNN hybrid inference |
Significant accuracy improvements on CIFAR100 dataset with noisy labels |
Using 2-norm on neural codes yields statistical advantages over classical SoftMax inference |
|
CNN-LSTM vs classical algorithms (SVM, standalone CNN) |
Superior categorization performance in texture classification |
CNN-LSTM outperforms SVM and CNN in accuracy and stability across datasets |
|
Self-distillation techniques |
Average accuracy boost of 2.65% across architectures and datasets |
Minimum 0.61% increase in ResNet, maximum 4.07% in VGG19 models |
FCNs have enabled real-time object detection and segmentation in robotics, industrial automation, and medical imaging, supporting the rapid growth of computer vision applications.
The evolution of segmentation techniques, driven by deep learning models, vision transformers, and fully convolutional networks, has set new standards for accuracy, speed, and adaptability. These advancements, showcased at CVPR 2025 and other leading conferences, highlight the importance of scaling image segmentation across diverse data and tasks. As computer vision continues to evolve, these techniques will remain at the forefront of AI and robotics innovation.
Image Segmentation Trends
Edge AI Integration
Edge AI is transforming computer vision by enabling real-time image segmentation directly on devices like cameras and robots. Engineers now deploy lightweight convolutional neural networks on edge hardware, such as Raspberry Pi and NVIDIA Jetson. These models use pruning and quantization to run efficiently, even with limited resources. A recent study showed that edge-based systems deliver high frame rates and low latency, making them ideal for applications like autonomous driving and intelligent surveillance. The table below highlights key aspects of Edge AI in computer vision:
|
Aspect |
Details |
|---|---|
|
Edge AI Models |
|
|
Real-time Processing |
Low latency inference on edge devices |
|
Advantages |
Bandwidth efficiency, energy savings, real-time alerts |
|
Challenges |
Limited power, heat management, computational constraints |
These advancements allow robots and smart devices to process visual data instantly, reducing reliance on cloud servers.
Cross-Domain Adaptation
Cross-domain adaptation helps computer vision systems perform image segmentation across different environments. Researchers use feature-level and image-level adaptation to align data from various sources. Combining these strategies improves segmentation accuracy, especially when the target domain differs from the training data. Recent analysis shows that methods like fused style transfer and incremental image mixing reduce domain gaps. Studies report significant gains in segmentation performance on benchmarks such as Cityscapes and ACDC. Self-supervised learning and self-supervised techniques further boost adaptability, allowing models to learn from unlabeled data and handle new scenarios.
Annotation Advances
Annotation advances have made computer vision more efficient. Weakly supervised learning now uses image-level labels, bounding boxes, and points to reduce manual annotation work. Vision foundation models, such as the Segment Anything Model, support promptable segmentation and expand annotation efficiency. The chart below shows high dice scores for tissue segmentation using sparse annotations:
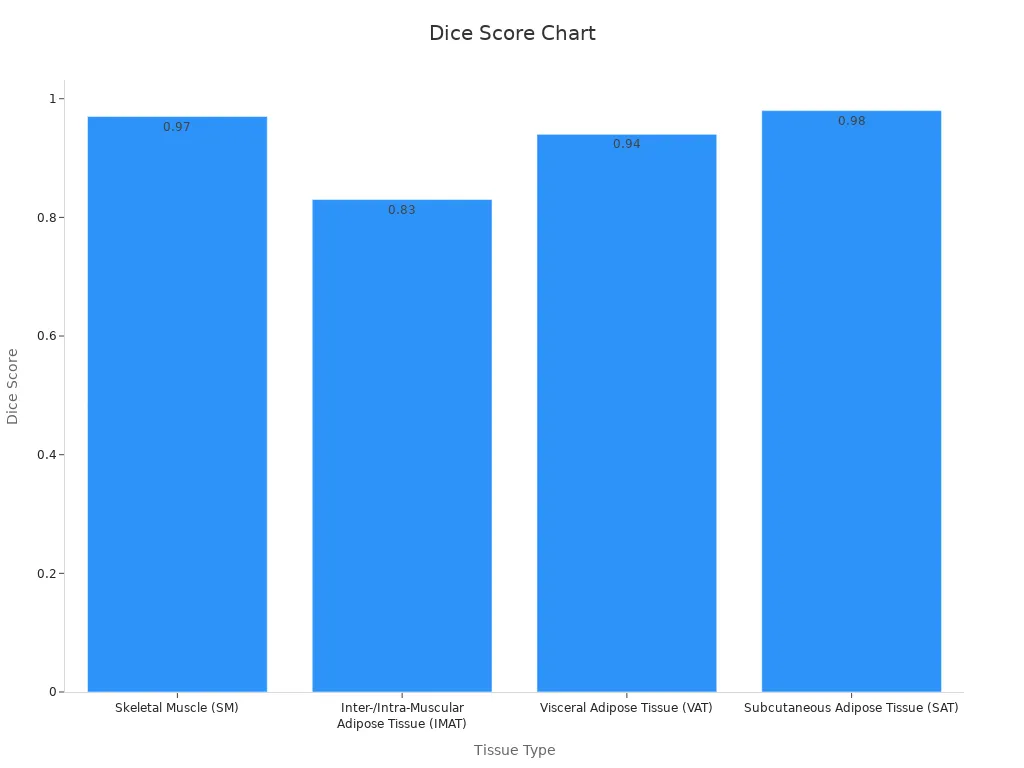
Self-supervised learning and annotation-efficient frameworks achieve high accuracy with less manual effort. Industry standards like inter-annotator agreement and F1 score help maintain annotation quality. These advancements drive faster, more reliable computer vision workflows across industries.
Real-Time Video Analysis

Real-time video analysis has become a cornerstone in the advancement of computer vision for AI and robotics. This technology enables machines to interpret and respond to dynamic environments with speed and precision. By leveraging object detection, tracking, and scene understanding, systems can make informed decisions in milliseconds. The following sections explore how real-time video analysis shapes autonomous vehicles, robotics applications, and industrial automation.
Autonomous Vehicles
Autonomous vehicles rely on computer vision to process video streams from multiple cameras and sensors. Real-time video analysis ensures that these vehicles can detect objects, track their movement, and react to changes on the road. Engineers use advanced metrics to measure performance and safety. The table below highlights key metrics that support reliable autonomous vehicle operation:
|
Metric Category |
Specific Metrics / Values |
|---|---|
|
Network-layer Metrics |
Packet loss rate, jitter, throughput, radio-level metrics (RSRP, RSRQ) |
|
Application-layer Events |
Video stalls, resolution changes, frame drops |
|
Perceptual Video Quality |
VMAF score (0-100), correlates strongly with human Mean Opinion Scores (MOS) |
|
AI QoE Prediction Model |
GRU-based RNN: RMSE = 1.62, MAE = 1.41 (less than 1.6% deviation on VMAF scale), inference latency ~66 ms |
|
End-to-End Latency |
Total teleoperation latency under 150 ms (including feature extraction, 5G hops, UI rendering) |
|
Forecast Horizon |
QoE forecast 2 seconds ahead, allowing ~1.9 seconds reaction time within latency budget |
These metrics demonstrate that real-time video analysis, supported by AI and network monitoring, maintains high video quality and low latency. This reliability is essential for safe and efficient autonomous driving.
Robotics Applications
Robotics applications benefit greatly from real-time video analysis. Companies like Realtime Robotics have developed hardware accelerators that process spatial data instantly. This technology allows robots to plan motion, avoid collisions, and adapt to new obstacles. The integration of computer vision with CAD data enables robots to coordinate in dynamic environments.
Key factors that improve robotic responsiveness include:
-
5G networks provide ultra-low latency and high bandwidth for video transmission.
-
Edge computing processes video data close to the source, reducing delays.
-
AI-driven robotics offload heavy analysis to edge or cloud servers, enabling quick responses.
-
Sensor networks combine video, lidar, and other data for enhanced perception.
These advances allow robots to perform object detection, tracking, and analysis in real time, improving safety and productivity in manufacturing and logistics.
Industrial Automation
Industrial automation uses computer vision and real-time video analysis to monitor production lines, inspect products, and ensure quality control. Modern systems employ parallel processing and GPU acceleration to handle intensive video analysis tasks. Sensor fusion combines video with data from other sources, such as depth sensors and IMUs, to provide a comprehensive view of the environment.
Industry leaders like Siemens and Amazon use optimized computer vision systems for predictive maintenance and warehouse automation. These systems rely on object detection and tracking to identify defects, monitor equipment, and manage inventory. Thorough testing in both simulations and real-world settings ensures that real-time video analysis meets the demands of industrial environments.
Note: Real-time video analysis continues to drive innovation in computer vision, enabling smarter, faster, and safer AI-powered systems across industries.
Applications
Medical Imaging
Medical imaging stands as one of the most impactful areas for image segmentation. Hospitals and clinics use segmentation to identify tumors, monitor disease progression, and plan surgeries. AI-driven algorithms now help radiologists outline organs and lesions with high precision. Clinical trials and reader studies validate these tools by comparing their results to expert radiologists. This process ensures that new segmentation methods remain accurate and reliable for patient care.
-
Common evaluation metrics include Dice Similarity Coefficient (DSC), Intersection-over-Union (IoU), and Average Hausdorff Distance (AHD). These metrics focus on true positive classifications and boundary accuracy, which are critical in medical images where regions of interest often occupy less than 10% of the image.
-
Segmentation supports tasks such as tumor detection and brain white matter characterization. These applications directly impact early diagnosis and treatment planning.
-
Technical evaluations use advanced methods like vision transformers and perceptual loss functions to improve segmentation quality. Public datasets and challenges, such as BRATS, provide benchmarks that drive innovation and ensure reproducibility.
Clinical validation, expert review, and standardized assessments help maintain scientific rigor and regulatory compliance in medical imaging.
Smart Manufacturing
Smart manufacturing uses image segmentation to optimize production lines and maintain high quality standards. Factories deploy AI and machine learning to inspect products, detect defects, and analyze complex data streams in real time. Automated Optical Inspection (AOI) systems now perform non-destructive quality checks, reducing human error and preventing defective products from reaching customers.
-
Clustering algorithms like K-means group similar data points, revealing hidden patterns and optimizing processes. Operations leaders report that clustering uncovers production line trends, leading to better yields and less downtime.
-
A McKinsey study found that advanced clustering analytics can reduce downtime by up to 15% and improve production yields by 20%.
-
Industry 4.0 integration demands smarter analytics that process multi-dimensional data streams. Real-time decision support allows instant adjustments based on live data, helping factories manage complexity and maintain efficiency.
The combination of segmentation, clustering, and real-time analytics drives continuous improvement in manufacturing environments. 🏭
Challenges
Data Annotation
Data annotation remains a major challenge in large-scale image segmentation projects. Teams working with datasets like COCO and OpenImages often face annotation noise. This noise includes incomplete or over-extended masks and unclear object boundaries. Human errors in tracing, ambiguous outlines, and biases from automated tools all contribute to noisy labels. Even a small mislabeling rate, such as 5% in cardiac chamber segmentation, can lead to serious clinical errors. Researchers have created benchmarks like COCO-N and CityScapes-N to study the effects of annotation noise. Results show that even modest noise levels can cause a noticeable drop in model accuracy. These findings highlight the need for better annotation protocols and noise-aware training.
-
Maintaining consistency among annotators proves difficult due to subjective interpretations and varying backgrounds.
-
Managing a large team of skilled annotators requires strong onboarding and workflow optimization.
-
Ensuring quality control across vast datasets is critical to prevent errors from spreading.
-
Balancing speed and accuracy is tough; automation tools help but need human validation.
-
Data privacy and security concerns arise, especially with sensitive information.
Computational Demands
Advanced segmentation models like Mask RCNN and U-Net deliver high accuracy but require significant computational resources. A review of deep learning segmentation techniques notes that computational complexity and hardware limitations remain key obstacles. For example, a Mask RCNN-based nuclei segmentation model processed over 2,000 nuclei in under an hour using a single NVIDIA Quadro P6000 GPU. Manual annotation would have taken days or weeks. This example shows the power of modern hardware but also highlights the need for access to high-performance GPUs. Many organizations struggle to scale these solutions due to cost and infrastructure limits.
Domain Adaptation
Domain adaptation presents another significant hurdle. Unsupervised domain adaptation in semantic segmentation struggles with the gap between synthetic and real images. Self-training methods rely on pseudo-labels, but differences in image domains reduce their accuracy. In medical imaging, domain shifts and data distribution differences make adaptation even harder. Transfer learning, normalization, and unsupervised learning each have limits. Normalization can reduce differences but may remove important image details. Deep learning models, including those using adversarial techniques or generative adversarial networks, often fail to generalize well to new domains. The lack of unified datasets and open-source algorithms makes it hard to compare methods and reproduce results. Future research must focus on better adaptation methods and standardized benchmarks.
Future Directions
Research Frontiers
Researchers continue to push the boundaries of image segmentation. They develop new models and techniques to solve current challenges. Some of the most promising research areas include:
-
Transformer-based models, such as Vision Transformers and Swin Transformer, use self-attention to understand images better. These models capture long-range relationships and improve segmentation accuracy.
-
EfficientNet-based models balance accuracy and size. They work well on mobile and edge devices, making real-time segmentation possible in robotics and smart cameras.
-
Multi-modal data integration combines RGB images with depth or thermal data. This approach helps in complex tasks like autonomous driving and medical imaging.
-
Lightweight architectures, including MobileNet and ENet, use pruning and quantization. These models enable fast, real-time segmentation for robotics and autonomous vehicles.
-
Advanced modules like PointFlow and foreground-scene modules improve object detection in cluttered scenes. They help models focus on important details and ignore background noise.
-
Foreground saliency guided loss functions prevent overfitting to simple backgrounds. This technique increases model robustness.
-
Relation networks and spatial modeling improve boundary detection, especially for small or crowded objects.
-
Hierarchical neural network search frameworks design custom architectures for remote sensing and aerial imagery.
Generative ai also plays a role in creating synthetic data for training and testing segmentation models. This approach helps overcome data shortages and improves model performance.
Industry Growth
The AI and robotics industry continues to grow rapidly, driven by advances in segmentation and generative ai. The table below highlights key segments and growth drivers:
|
Segment |
Key Insights and Growth Drivers |
|---|---|
|
Service Robots |
Largest market share in 2023; automation demand in service industries; AI capabilities like NLP, CV, ML |
|
Industrial Robots |
Fastest CAGR forecast; smart factories and Industry 4.0; real-time monitoring and predictive maintenance |
|
Machine Learning |
Largest revenue share in 2023; enables autonomous decision-making and performance improvement |
|
Edge Computing |
Fastest growth expected; supports IoT data processing near source, reducing latency and bandwidth needs |
|
Automotive Segment |
Largest revenue share in 2023; growth driven by autonomous vehicles and smart transportation solutions |
|
Regional Deployment |
73% of new industrial robots installed in Asia (2022), showing strong regional growth |
Industry experts project a 7.3% CAGR for AI and robotics from 2025 to 2032. Some forecasts predict over 20% CAGR due to new technologies and cross-industry partnerships. Companies use generative ai to create new products, improve automation, and personalize customer experiences. These trends shape the future of smart factories, healthcare, and transportation.
Recent reviews highlight how deep learning, CNNs, and transformers have transformed image segmentation, improving accuracy and automation in fields like healthcare and robotics. Researchers continue to address challenges such as data scarcity and computational costs, while new models like lightweight architectures and federated learning drive progress.
-
AI-powered segmentation enables better decision-making by extracting insights from large datasets.
-
Continuous refinement of segmentation strategies leads to higher accuracy and improved outcomes.
-
Explainable models increase trust and transparency in industrial and business systems.
Professionals should stay updated, experiment with new methods, and contribute to ongoing innovation. The future of image segmentation depends on active learning and collaboration across the AI community.
التعليمات
What is image segmentation in AI?
Image segmentation divides an image into different parts or regions. Each region shows a specific object or area. AI uses this process to help machines understand what they see in pictures or videos.
Why does robotics need image segmentation?
Robots use image segmentation to find and track objects. This skill helps robots move safely, pick up items, and avoid obstacles. Accurate segmentation improves robot performance in real-world tasks.
How do deep learning models improve segmentation?
Deep learning models learn patterns from large datasets. These models find edges, shapes, and textures in images. This learning helps them create more accurate and detailed segmentations than older methods.
What challenges do teams face with data annotation?
Teams often struggle with noisy labels and inconsistent boundaries. Human errors and unclear images make annotation hard. High-quality annotation takes time and careful review.
Can image segmentation work in real time?
Yes, modern AI models and edge devices process images quickly. Real-time segmentation supports self-driving cars, smart cameras, and robots. Fast processing helps machines react to changes right away.