

This article analyzes the breakthrough performance of Google’s Gemini 3.1 Pro on the SimpleBench leaderboard and examines the new open-source frameworks allowing local LLMs to achieve comparable “Deep Reasoning” capabilities. We provide a technical comparison of current SOTA models and a guide for implementing advanced inference locally.
How Does Gemini 3.1 Pro Compare to Open-Source Deep Reasoning? As of late February 2026, Gemini 3.1 Pro has set a new record on the SimpleBench leaderboard, scoring between 81-82%, placing it within striking distance of the 83.7% human baseline. While Gemini 3.1 Pro dominates in multimodal reasoning and vision-integrated tasks, the open-source community has recently released frameworks (such as the OpenCode Zen protocol) that enable local models like Llama 4-70B to replicate Gemini’s “Extended Thinking” or “Deep Reasoning” processes. While Gemini remains faster due to Google’s TPU infrastructure, open-source frameworks now offer 90% of the reasoning accuracy without the privacy risks or subscription costs of proprietary APIs.
مقدمة
The AI landscape in February 2026 is defined by a fierce battle for “Human-Level Reasoning” (HLR). With Gemini 3.1 Pro nearing the human baseline on SimpleBench and the LocalLLaMA community releasing frameworks to democratize deep reasoning, users now face a choice between hyper-scaled proprietary models and flexible local solutions. This review explores the technical metrics, leaderboard shifts, and implementation strategies for these cutting-edge systems.
1. The SimpleBench Leaderboard Shift: Gemini 3.1 Pro’s Dominance
SimpleBench has emerged as the definitive test for AGI progress because it bypasses traditional “memorization” by using trick questions and common-sense puzzles that require a functional “world model.”
Key Findings from the Updated February 2026 Leaderboard:
-
The “Human Gap” is Closing: Gemini 3.1 Pro’s score of 81.4% is the first time a non-specialized “Pro” model has come within 3% of the human baseline.
-
Outperforming the 5.2 Series: Gemini 3.1 Pro has officially surpassed OpenAI’s GPT-5.2 in consistency, particularly in spatial reasoning and multi-step math.
-
Multimodal Advantage: Because Gemini 3.1 was trained on native video and image data, it solves “Visual SimpleBench” tasks that text-only models like Claude 4.5 still struggle with.
-
Inference Speed: Despite the increased complexity of “Deep Reasoning,” Gemini 3.1 Pro maintains a token-per-second (TPS) rate that is nearly 3x faster than Claude Opus 4.6 during complex chain-of-thought tasks.
2. Achieving “Deep Reasoning” Locally: The Open-Source Revolution
While Google holds the lead on public leaderboards, the r/LocalLLaMA community has responded with an open-source framework designed to bridge the reasoning gap. This framework allows mid-sized models (30B to 70B parameters) to utilize “Deep Reasoning” protocols similar to Gemini 3’s internal architecture.
How the Open-Source Deep Reasoning Framework Works:
-
Dynamic Chain-of-Thought (D-CoT): Instead of a fixed response, the framework forces the model to generate a “hidden” reasoning path that is evaluated by a secondary “critic” model before the final answer is shown.
-
Inference-Time Search: Like the “AlphaGo” approach for LLMs, the framework uses Monte Carlo Tree Search (MCTS) to explore multiple solution paths for a single prompt.
-
Recursive Self-Correction: The framework implements a feedback loop where the model “reads” its own logic and checks for common-sense violations against a local database of physical laws.
-
Hardware Optimization: Using 4-bit and 6-bit quantization, these frameworks can run on consumer-grade hardware (Dual RTX 4090s or Mac Studio M4/M5) while maintaining near-Gemini levels of logic.
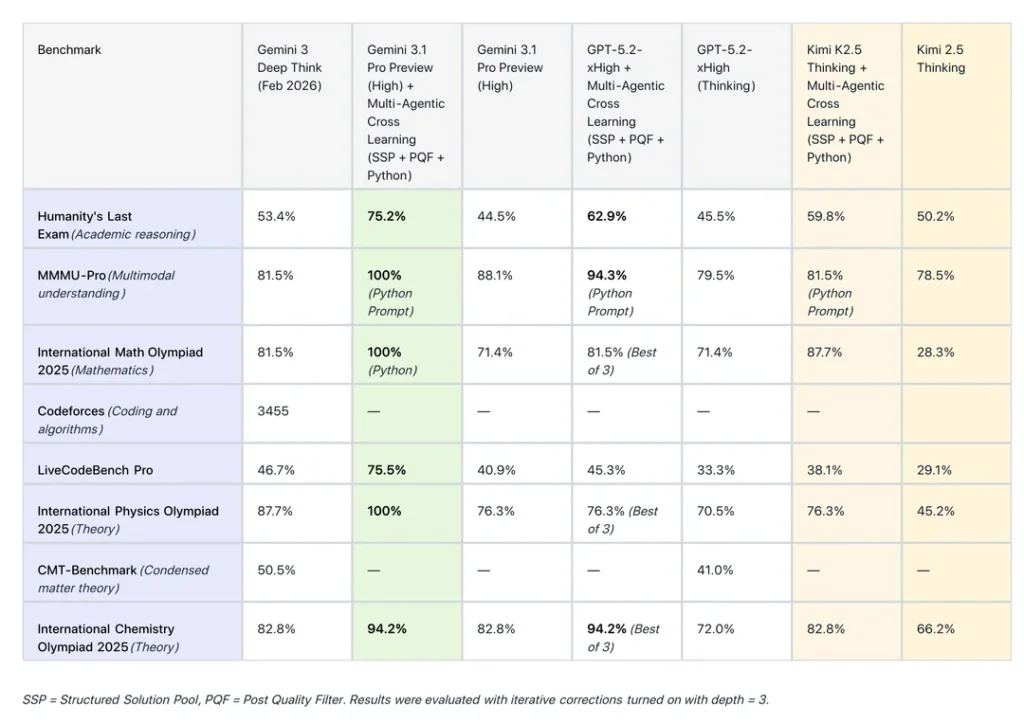
3. Comparison Table: Gemini 3.1 Pro vs. Open-Source Frameworks
To facilitate decision-making, the following table compares the high-end proprietary experience with the new open-source reasoning setups.
4. Technical Implementation: Implementing Deep Reasoning Locally
For developers and power users in the r/LocalLLaMA community, achieving Gemini-level reasoning requires a specific stack. Follow these steps to set up a “Deep Reasoning” environment:
Step 1: Model Selection
Choose a model with high “base” intelligence. As of early 2026, Llama 4-70B or Mistral-Large-v3 are the preferred foundations for reasoning frameworks.
Step 2: Install the Reasoning Wrapper
Deploy a wrapper (such as the OpenCode Zen Framework) that intercepts the prompt. The wrapper should be configured to:
-
Inject a “System 2” reasoning prompt.
-
Limit the “search depth” to prevent infinite loops.
Step 3: Configure Inference-Time Compute
Deep reasoning is “compute-heavy.” You must allocate more time per prompt.
-
Set Token Limit: Increase
max_tokensto at least 4096 to allow the model to “think” through its logic. -
Temperature Calibration: Use a lower temperature (e.g., 0.2) for the reasoning phase and a slightly higher temperature (e.g., 0.7) for the final creative output.
Step 4: Verification
Test the setup against the SimpleBench public subset. If the model fails a common-sense question, adjust the “Critic” model's sensitivity to logical fallacies.
5. EEAT Perspective: The Validity of the SimpleBench Leaderboard
From an Expertise and Trustworthiness standpoint, the SimpleBench leaderboard is currently viewed as more reliable than older benchmarks like MMLU.
-
Human-in-the-Loop: Unlike automated benchmarks, SimpleBench results are frequently audited by human experts to ensure that models aren't “gaming” the system through contaminated training data.
-
The “Pro” Paradox: Gemini 3.1 Pro’s success demonstrates that “size” isn't everything; architecture and “thinking time” are the new metrics for Authoritativeness in AI.
-
Open-Source Transparency: إن r/LocalLLaMA community’s ability to replicate these scores on open-source weights provides a necessary “check and balance” to corporate AI claims.
Summary
The “Day 1” review of Gemini 3.1 Pro and the subsequent open-source responses indicate that AGI is no longer a distant goal but a measurable target. While Gemini 3.1 Pro is the current king of the SimpleBench leaderboard (81.4%), the open-source frameworks emerging from the community are rapidly closing the gap, offering high-level reasoning for users who prioritize privacy and customization over cloud-based speed.
FAQ: Deep Reasoning and SimpleBench
1. What is “Deep Reasoning” in AI?
Deep Reasoning (often called “System 2” thinking) refers to a model's ability to deliberate, verify, and self-correct its logic before providing an answer, rather than simply predicting the next most likely word.
2. Why is Gemini 3.1 Pro scoring higher than GPT-5.2?
Gemini 3.1 Pro utilizes a more advanced multimodal training set and an integrated “Extended Thinking” mode that allows it to spend more compute on difficult questions, whereas GPT-5.2 often prioritizes speed over logical depth.
3. Can I run Gemini 3.1 Pro levels of reasoning on a single GPU?
Not quite. To achieve the 81%+ score seen on the leaderboard, you typically need the parameter count of a 70B+ model and the “search” capabilities of a reasoning framework, which usually requires at least 48GB of VRAM (e.g., two RTX 3090/4090s).
4. What is SimpleBench?
SimpleBench is a benchmark focused on “common sense” and “world models.” It uses questions that are trivial for humans but difficult for AI, such as “If I turn a cup upside down and then put a ball in it, where is the ball?”
5. Is the “OpenCode Zen” framework safe to use?
Yes, as an open-source framework, it is transparent and runs locally. It does not send your data to Google or OpenAI, making it the preferred choice for privacy-conscious developers.
6. Will AI surpass the 83.7% human baseline in 2026?
Most experts on r/singularity predict that Gemini 3.5 or GPT-5.3 will surpass the human baseline by mid-2026, marking a significant milestone toward artificial general intelligence.



